Apple готовится к анонсу сразу трёх новых устройств с чипом M5, который должен заменить M4. Однако, вопреки ожиданиям, новая SoC может быть создана не на современном техпроцессе N3P, как A19 и A19 Pro, а на предыдущей версии N3E, как и чип M4. Об этом сообщает свежий отчёт, вызывающий вопросы среди экспертов.
Такой шаг может объясняться ростом цен на производство у TSMC. Согласно данным, вафли на базе N3P стоят $27 000, тогда как N3E обойдётся «всего» в $25 000. Возможно, Apple решила сэкономить на массовом производстве, особенно учитывая, что конкуренции в классе M5 сейчас практически нет — чип останется уникальным решением для новых Mac и iPad Pro.
Тем не менее, аналитики сомневаются в достоверности информации. Ранее Apple всегда делала ставку на передовые технологии, включая переход на 3 нм в чипах A17 Pro и всей линейке M3. Их производство велось на более дорогом, но технологичном процессе N3B — даже несмотря на затраты более $1 млрд только на запуск.
Если M5 действительно будет основываться на устаревшем техпроцессе, это станет необычным шагом для Apple, которая традиционно выбирает самые свежие литографии. Но в ситуации, когда Apple уже вывела A19 и A19 Pro на техпроцессе N3P, логичнее предположить, что и M5 создаётся по тому же стандарту, а упоминание N3E — просто ошибка в отчёте.
Бывший CEO Intel Пэт Гелсингер прокомментировал последние инвестиционные соглашения компании с NVIDIA и администрацией США, заявив, что они не приносят реальной пользы для развития фабричного бизнеса. По его словам, смысл господдержки или стратегических сделок с другими компаниями имеет значение только в том случае, если это приводит к строительству и загрузке новых производственных мощностей Intel.
Гелсингер подчеркнул, что в рамках текущих соглашений нет обязательств по размещению заказов на производство чипов в рамках Intel Foundry Services (IFS). Несмотря на позитивную реакцию рынка на анонс инвестиций, ни NVIDIA, ни AMD, ни правительство США пока не закрепили контрактов на использование фабрик Intel. Это ставит под сомнение эффективность привлечённых средств в контексте долгосрочной стратегии компании.
Он также напомнил, что архитектура Intel 18A, разработанная по инициативе «5N4Y», стала первым заметным результатом пятилетней трансформации, которую он начал после прихода в компанию. Однако, несмотря на прогресс, Гелсингер выразил разочарование по поводу задержек с финансированием со стороны Минторга США, что затормозило реализацию инициатив, поддержанных CHIPS Act.
По мнению бывшего главы Intel, текущая стратегия должна быть сосредоточена не только на привлечении инвестиций, но и на жёсткой увязке финансирования с загрузкой производственных линий, иначе усилия по восстановлению технологического лидерства останутся незавершёнными.
На фоне слухов об исчезновении Xbox из магазинов в США компания Microsoft заявила, что не прекращает сотрудничество с Target и Walmart, а все текущие партнеры остаются в игре. Поводом для спекуляций стал анонимный пост на Reddit о якобы снятии стендов Xbox в одном из магазинов Target.
После этого несколько сайтов запустили волну публикаций о «закате Xbox», сославшись на случаи отсутствия консолей в отдельных розничных точках. Однако, как выяснилось позже, на складах многих Walmart и GameStop консоли всё ещё присутствуют, особенно модель Xbox Series S. Продажи Xbox Series X остаются ограниченными, поскольку Microsoft старается избегать перепроизводства, а часть чипов идёт на серверы Xbox Cloud Gaming.
Представители Target и Walmart официально опровергли информацию о прекращении продаж, а Microsoft подчеркнула, что не намерена уходить с рынка консолей. Также отмечено, что недавние повышения цен на Xbox Series X/S и подписку Game Pass связаны с тарифами и экономическими факторами, но это не сигнал к сворачиванию бизнеса.
Слухи о прекращении поддержки Xbox подогреваются на фоне негативного фона вокруг компании — увольнений, роста цен и резкой критики от пользователей, но Microsoft настаивает на долгосрочных планах в сфере аппаратного обеспечения и продолжении сотрудничества с AMD.
Учёные из Тайваня, совместно с крупнейшими университетами и производителем чипов TSMC, разработали новый тип компьютерной памяти, который сочетает высокую скорость, энергоэффективность и долгий срок хранения данных. Это может серьёзно повлиять на развитие смартфонов, систем ИИ и даже автомобильной электроники.
Речь идёт о технологии SOT-MRAM — это современный вид памяти, который способен работать так же быстро, как оперативная память, но при этом не стирается при выключении питания, как флешка. Проблема была в том, что материал, на котором основана эта память, терял свои свойства при производстве чипов. Команда учёных из Национального университета Ян Мин Чяо Тун и других организаций нашла способ сохранить этот материал стабильным, даже при нагреве.
Они создали рабочий чип с памятью на 64 килобита, который:
Работает в 1000 раз быстрее, чем обычная флеш-память
Не требует постоянного питания для хранения данных
Сохраняет информацию более 10 лет
Подходит для массового производства
Такой тип памяти может заменить существующие решения в смартфонах, ноутбуках, электромобилях и серверных центрах, особенно там, где важна экономия энергии и надёжность хранения. Тайвань делает важный шаг к будущему, в котором устройства будут работать дольше, быстрее и безопаснее.
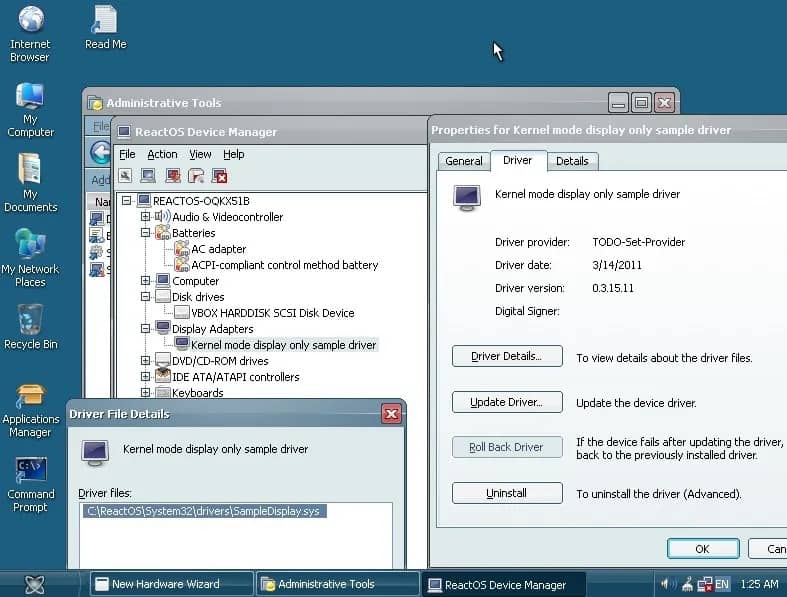
Проект ReactOS, ориентированный на создание открытой альтернативы Windows с совместимостью на уровне ABI, начал активную работу по поддержке графических драйверов WDDM — архитектуры, используемой в Windows, начиная с Vista. До сих пор система была ограничена поддержкой XDDM, но для работы с современным оборудованием переход на Windows Display Driver Model становится необходимым.
Несмотря на то, что ReactOS остаётся в рамках архитектуры Windows Server 2003, разработчики признают, что без поддержки WDDM операционная система рискует остаться несовместимой с актуальными GPU. Открытый разработчик под псевдонимом The_DarkFire_ сообщил, что ему удалось загрузить BasicDisplay.sys и запустить базовые функции отображения через драйвер WDDM.
По его словам, WDDM оказался "удивительно терпимым", и даже минимальная инициализация позволяла добиться вывода изображения на современные мониторы с родным разрешением и частотой обновления. Однако дальнейший прогресс упёрся в ограничения поддержки низкоуровневого железа и ядра Win32k.
Эти эксперименты показывают, что в перспективе ReactOS сможет работать с современными видеокартами и интерфейсами, если удастся реализовать полноценную поддержку WDDM. Пока речь идёт только о начальных тестах, но это один из важнейших шагов для выхода проекта за пределы устаревшей платформы.
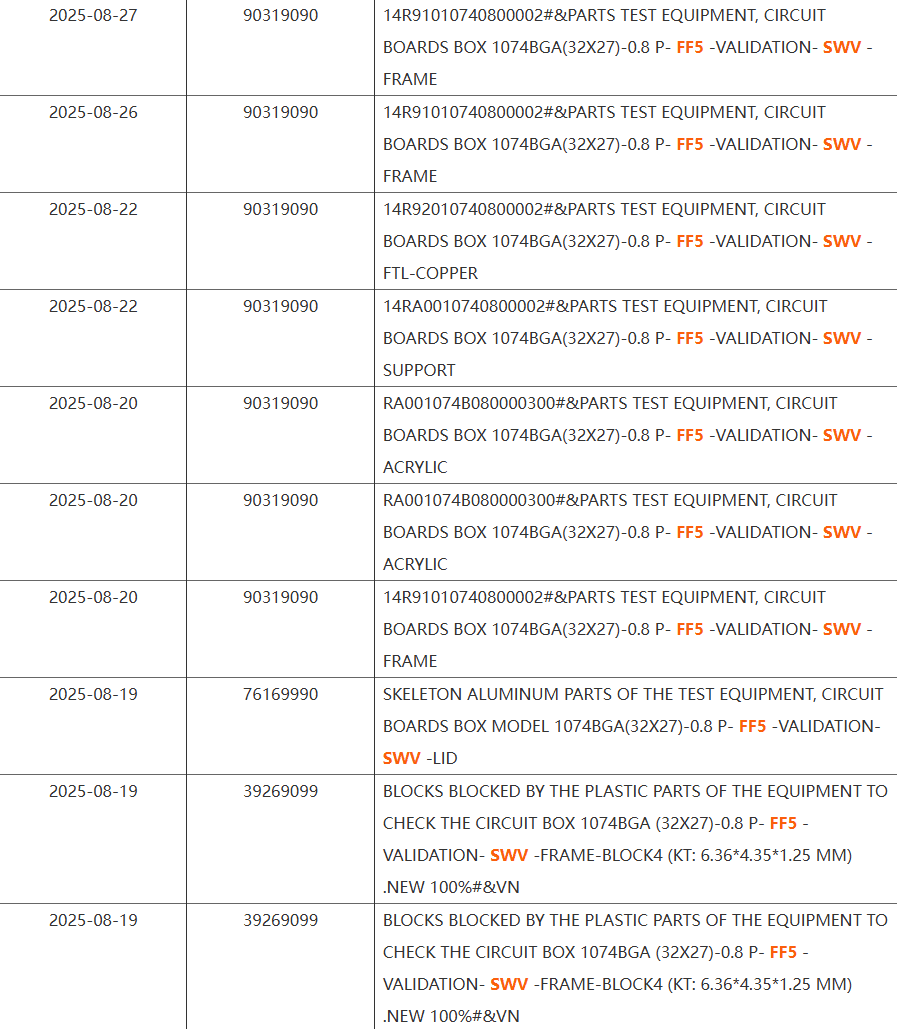
Компания AMD готовит собственную линейку ARM-базированных мобильных APU, которые фигурируют под кодовым именем Soundwave. Согласно появившимся отгрузочным документам, разработки уже вышли на ранний этап тестирования. Новый чип должен выйти в 2026 году и ориентирован на сегмент Windows on ARM, где сегодня доминируют SoC от Qualcomm.
Согласно утечке, продукт использует BGA-разъём 1074, что указывает на форм-фактор мобильного APU, а не другого типа кристалла. Размер упаковки — 32×27 мм, что типично для компактных решений. Также подтвержден шаг контактов 0,8 мм и новый разъём FF5, который придёт на смену FF3, применяемому, например, в Steam Deck. Все эти характеристики указывают на полностью новую платформу.
Линейка Soundwave станет первой ARM-платформой AMD с 2014 года, когда был отменён проект Skybridge. Сегодня экосистема ARM под Windows стала гораздо зрелее, чему способствовал выход Snapdragon X Elite. Учитывая наращивание производительности в x86-сегменте — например, с Ryzen Strix Halo — расширение в ARM-направление выглядит логичным шагом со стороны AMD.
Конкуренция в секторе AI PC и компактных устройств усиливается. NVIDIA также готовит собственные ARM-чипы, и AMD явно не намерена оставаться в стороне. Официальных сроков запуска пока нет, но всё указывает на дебют в течение следующего года.
С 14 октября 2025 года, уже завтра, Microsoft окончательно прекращает поддержку операционной системы Windows 10. Это означает конец выпуска обновлений безопасности, новых функций и технической поддержки. Пользователям и компаниям придётся либо срочно переходить на Windows 11, либо остаться с системой, которая больше не защищена от уязвимостей.
Для стран Европейской экономической зоны (EEA) предусмотрена однолетняя бесплатная программа Extended Security Updates (ESU) — благодаря юридическим требованиям Microsoft согласилась продлить поддержку до 2026 года. Однако в остальном мире такие обновления доступны только по платной подписке, что создаёт серьёзные трудности для глобальных компаний, особенно если они работают в разных юрисдикциях.
Эксперты из BeyondTrust предупреждают: несмотря на улучшение безопасности в последних версиях Windows 10, уязвимости продолжают появляться. Продолжать использовать ОС без поддержки — высокий риск для данных и инфраструктуры. Особенно это критично для оборудования, которое не поддерживает требования Windows 11 — наличие TPM и Secure Boot. Такие устройства станут необновляемыми и уязвимыми, а в будущем — просто устаревшими.
Остаётся меньше суток до отключения официальной поддержки. Организациям рекомендуется срочно оценить уровень риска, начать миграцию на поддерживаемые платформы и разработать стратегию защиты. Учитывая масштаб распространения Windows 10, речь идёт о десятках миллионов компьютеров, которые уже завтра окажутся вне зоны безопасности.
На платформе Kickstarter началась кампания по сбору средств на устройство Humbird 3, представляющее собой док-станцию с интерфейсом Thunderbolt 5, ориентированную на работу с полноразмерными видеокартами. Производитель заявляет поддержку любых GPU с TDP до 380 Вт, включая модели уровня GeForce RTX 4090 и Radeon RX 7900 XTX.
Внутри устройства используется контроллер Intel JHL9480, обеспечивающий пропускную способность до 120 Гбит/с. Это позволяет использовать PCIe x16 видеокарты в полноценном режиме с подключением через Thunderbolt 5 к ноутбукам и ПК. В корпус встроены блок питания мощностью 500 Вт, три порта Thunderbolt 5, DisplayPort 2.1, порты USB-A, слот SD/microSD, 1G Ethernet, а также беспроводная зарядка с автоматическим переключением стандартов. Для управления предусмотрен 1-дюймовый цветной дисплей и простая система мониторинга, основанная на собственной прошивке производителя.
В комплект входят: кабель Thunderbolt 5, адаптер питания на 180 Вт, кабель питания для GPU (12VHPWR 500 Вт) и документация. Поддерживается ручное управление вентиляторами и режим полной остановки при низкой нагрузке. Устройство поставляется в ноябре 2025 года.
На момент публикации действуют три основных уровня поддержки:
Super Early Bird ($299) — скидка $100 от рекомендованной розничной цены ($399). Почти все устройства по этой цене уже зарезервированы.
Early Bird ($309) — скидка $90, осталось менее 10 единиц.
Kickstarter Discount ($319) — скидка $80, в наличии около 20 штук.
К итоговой стоимости добавляется доставка в размере $20–30, сумма зависит от региона и возможных таможенных пошлин.
Устройство совместимо с большинством современных видеокарт, а также с другими PCIe-картами — от SSD до плат захвата. Производитель обещает уровень производительности, близкий к стационарным решениям при подключении к ноутбукам, но фактические тесты пока не опубликованы.
В сети появилось фото очередного вопиющего случая неаккуратной установки серверного процессора AMD EPYC. На изображении видно, что сокет SP5 полностью залит термопастой, причём состав проник между контактами и по всей монтажной области. Судя по степени загрязнения, речь идёт не о случайной ошибке, а о грубом нарушении всех правил сборки.
Сокет SP5, предназначенный для процессоров AMD EPYC серии Genoa и Bergamo, представляет собой сложную конструкцию с плотной посадкой контактов. Попадание термопасты вглубь разъёма может привести к замыканию, нестабильной работе или полной неработоспособности системы. Особую опасность представляют токопроводящие составы, но и обычные пасты затрудняют контакт, вызывая сбои при загрузке и под нагрузкой.
Пользователи Reddit, обсуждая снимок, назвали это типичным примером рукожопой сборки, недопустимой при работе с дорогим серверным железом. Один из комментаторов отметил, что исправление такой ошибки требует полного демонтажа, многочасовой чистки и не гарантирует восстановления работоспособности.
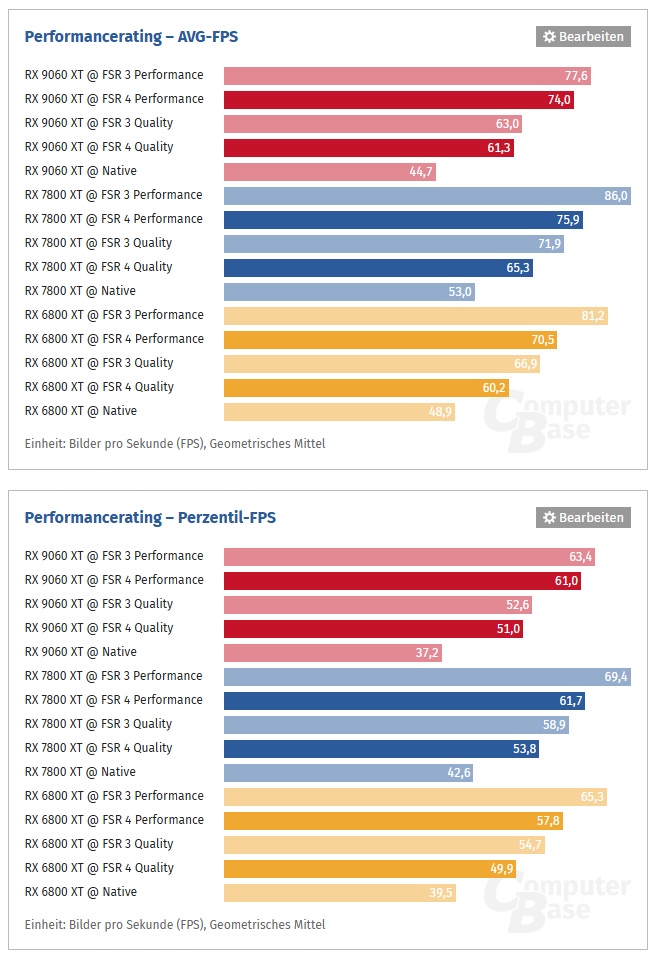
ComputerBase.de провёл тесты неофициальной версии FSR 4 INT8 на видеокартах Radeon RX 6000 и RX 7000, и обнаружил, что даже без поддержки расширенных AI-инструкций новая технология заметно превосходит FSR 3.1. Картинка стала гораздо чётче и стабильнее, особенно в сложных сценах. Разница между апскейлингом FSR 3.1 и новым FSR 4 — буквально как день и ночь, хотя до оригинального варианта на RDNA 4 с FP8 аппроксимацией всё же есть отставание.
INT8 и FP8 — это форматы представления чисел с пониженной точностью, используемые в AI-вычислениях. INT8 (8-битные целые числа) применяются на RDNA 2 и RDNA 3, где отсутствует полная поддержка AI-инструкций. FP8 (8-битная плавающая точка) доступна только на RDNA 4, и именно она обеспечивает максимальное качество и производительность благодаря аппаратному ускорению. В результате FSR 4 FP8 на RX 9000 работает быстрее и даёт лучшую картинку, тогда как INT8-версия — это «облегчённая» альтернатива, но всё равно значительно лучше FSR 3.1.
В режиме Performance RX 9060 XT теряет всего 5% FPS по сравнению с FSR 3.1, RX 7800 XT — 12%, RX 6800 XT — 13%. При этом FSR 4 Quality всегда быстрее нативного рендеринга и показывает стабильную картинку без серьёзных искажений. Но FSR 4 INT8 пока не является официальным решением: его установка требует ручной замены файлов, возникают проблемы совместимости, в некоторых играх — вылеты и графические артефакты, особенно если включена античит-система.
Тем не менее, FSR 4 даже в таком виде — огромный шаг вперёд. Он наглядно показывает, каким может быть будущий апскейлинг на RDNA 2 и RDNA 3. При снижении производительности на 5–13%, игрок получает заметно более чёткое и стабильное изображение по сравнению с FSR 3.1.
Останется только один вопрос: решится ли AMD официально выпустить FSR 4 Light для RDNA 2 и RDNA 3, или оставит эту технологию эксклюзивом RDNA 4? Пока ответа нет, но потенциал очевиден.