Компания EXO Labs представила EXO 1.0 — открытую платформу для запуска больших языковых моделей (LLM) на разнородной вычислительной технике, включая десктопы, серверы и даже смартфоны. Новый демо-проект продемонстрировал, как две станции NVIDIA DGX Spark могут работать в паре с Apple Mac Studio на чипе M3 Ultra, формируя единое решение для ускоренного вывода моделей. Вместо монолитного подхода EXO реализует дизагрегированный вывод, распределяя различные этапы обработки между системами — предварительный анализ (prefill) поручается GPU-системе, а генерация токенов (decode) — высокоскоростному чипу Apple.
В системе использовалась 10-гигабитная сеть Ethernet для потоковой передачи данных KV-кэша, что позволило одновременно задействовать оба устройства без простоев. Концепция базируется на различии в характере нагрузки: этап prefill требует высокой вычислительной мощности, в чём хорош DGX Spark с 100 TFLOPS (fp16), а decode — зависим от пропускной способности памяти, где M3 Ultra с 819 ГБ/с выигрывает. В тесте на модели Llama 3.1 8B гибридная система достигла почти троекратного ускорения по сравнению с Mac Studio, при этом обеспечив производительность на уровне Spark в prefill и рекордное время генерации на этапе decode.
EXO Labs продвигает идею гибкого масштабирования ИИ без необходимости в дорогостоящем едином ускорителе. Подобную архитектуру уже начинает развивать NVIDIA в рамках платформы Rubin CPX, где разные чипы обрабатывают prefill и decode раздельно. Но EXO делает это уже сейчас — на открытом ПО и потребительском «железе». Пока версия 1.0 доступна только по приглашениям, но это первый шаг к миру, где ИИ может использовать любую технику — эффективно и масштабируемо.
Система на базе Ryzen 5 8500G и материнской платы ASUS B850M-A YW GAMING WIFI показала стабильную работу с памятью DDR5-10600, что соответствует 5300 МГц по фактической частоте. Использовалась пара модулей G.SKILL 2×24 ГБ с профилем EXPO CL26 и напряжением 1.580 В.
На скриншотах MemTestPro показано 200% покрытия на всех 16 потоках без единой ошибки, что полностью подтверждает стабильность работы. Тайминги составили 50-58-58-110-160, контроллер памяти работал на 2650 МГц, CR — 2T. Платформа использовала прошивку с микрокодом AGESA ComboAM5PI 1.1.7.0.
Результат выделяется не только высокой частотой, но и общим объёмом памяти — 48 ГБ, что подчёркивает надёжность AM5 с Phoenix 2 даже при экстремальных настройках. Это один из самых стабильных разгонов DDR5 на бюджетном APU, зафиксированных с полным прохождением теста.
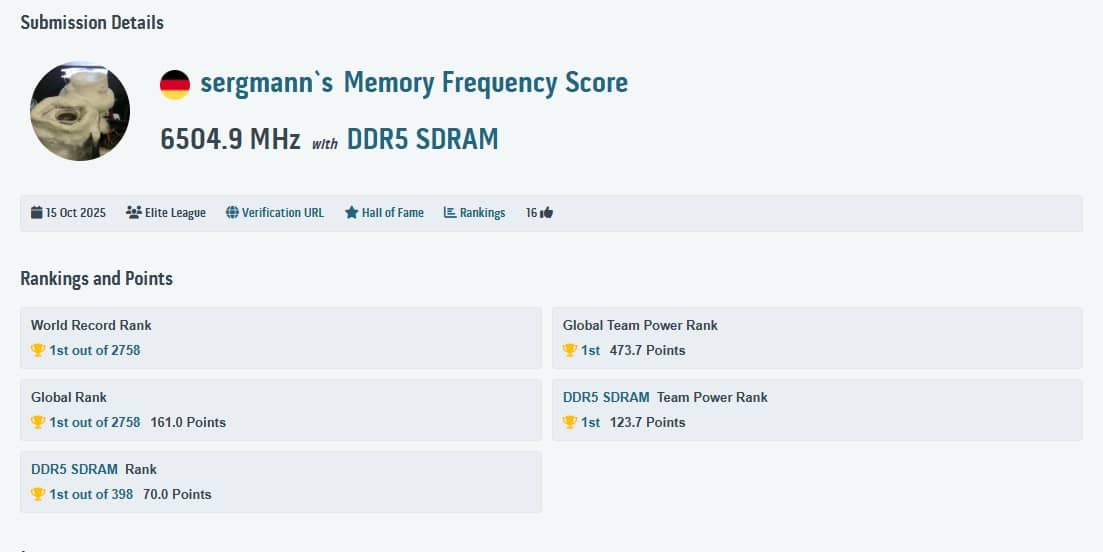
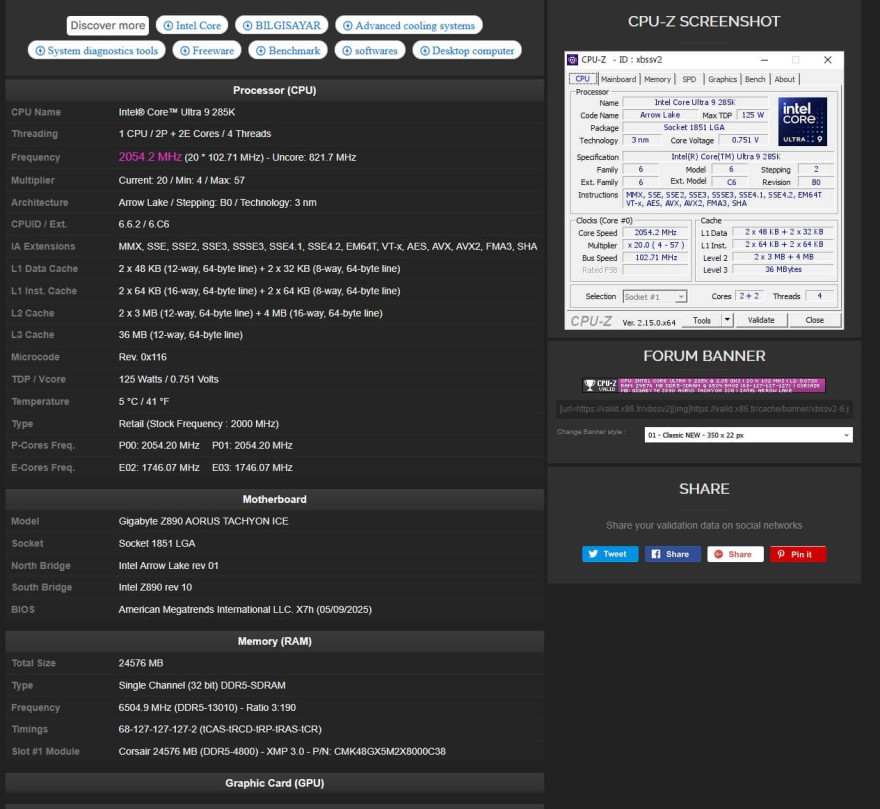
В категории экстремального разгона оперативной памяти установлен новый мировой рекорд — 13 009,8 МГц эффективной частоты DDR5. Этот результат стал первым в истории разгоном, преодолевшим психологическую отметку в 13 ГГц. Частота была достигнута на модуле DDR5 SDRAM от Corsair, охлаждаемом жидким азотом, в условиях стендового теста с ручной настройкой таймингов.
Платформой для рекорда стал новейший процессор Intel Core Ultra 9 285K Arrow Lake-S, работающий с пониженной частотой 2054 МГц по P-ядрам. Чип установлен на материнской плате Gigabyte Z890 Aorus Tachyon Ice, которая была выбрана за счёт высокой стабильности напряжения под экстремальной нагрузкой. Вся система питалась от блока Seasonic PRIME TX мощностью 1600 Вт, обеспечивающего достаточный резерв тока при пиковых нагрузках.
По итогам тестирования результат был официально подтверждён и занесён в глобальный рейтинг HWBOT, где он получил 1-е место среди 2758 участников в общем зачёте и 1-е место в категории DDR5. Также обновлён командный рейтинг по мощности, где рекорд обеспечил первое место в обоих зачётах с совокупными баллами 473,7 и 123,7 соответственно.
Важно отметить, что частота в 13 ГГц — это удвоенная эффективная частота памяти, основанная на реальной тактовой частоте ~6505 МГц. Но именно такой формат используется для сравнения пропускной способности модулей в современных системах, и текущий рекорд официально признан первым 13-гигагерцевым разгоном DDR5.
SUS официально запустила новую версию компактного игрового ПК серии ROG NUC под названием ROG NUC 9 MINI, построенную на базе мобильного процессора Ryzen 9 9955HX3D с 16 ядрами Zen 5 и технологией 3D V-Cache второго поколения. Этот чип, ранее считавшийся исключительно ноутбучным, теперь используется в десктопном мини-ПК, обеспечивая производительность уровня настольных систем в формате объёмом всего 3 литра.
При этом видеокарта в AMD-версии уступает Intel-моделям — вместо RTX 5080, как у Intel Core Ultra 9, используется RTX 5070 Laptop с 8 ГБ памяти, что указывает на приоритет Intel-сборок в линейке ROG NUC. Тем не менее, AMD-система превосходит Intel-аналоги по другим параметрам: она поддерживает до 96 ГБ DDR5-5600, в то время как у Intel — максимум 64 ГБ. Объём хранилища также увеличен до 4 ТБ через PCIe 5.0, против 2 ТБ у предыдущих моделей.
Система оснащена широким набором портов: USB 4.0, HDMI 2.1, DisplayPort 2.1, 2.5Gb Ethernet, а также встроенными модулями WiFi 7 и Bluetooth 5.4. Энергопотребление ограничено 75 Вт для процессора и 115 Вт для GPU, что позволяет сохранить оптимальный баланс температуры и производительности в условиях миниатюрного корпуса.
Несмотря на приставку “MINI”, корпус остался прежним по размеру, но получил улучшенное охлаждение с тройным тепловым трактом и активной вентиляцией. Новинка доступна по цене около 14 999 юаней (~$2100) и пока представлена только в Китае.
Компания Tachyum представила обновлённые планы по выпуску процессора Prodigy, повысив число универсальных ядер до 256 на один чиплет. Это уже третий пересмотр конфигурации — ранее речь шла о 192 и 128 ядрах соответственно. Архитектура теперь строится на базе многочиплетного SiP-дизайна, призванного достичь многократного превосходства над топовыми x86 и GPGPU-чипами для ИИ и HPC. Однако, несмотря на амбициозные заявления, финальные характеристики чипа всё ещё не зафиксированы, и тапаут не произведён, что делает заявленную производительность теоретической.
Параллельно компания сообщила о закрытии раунда финансирования серии C на сумму $220 млн от европейского инвестора. Он же разместил предварительный заказ на Prodigy на сумму $500 млн, что должно покрыть расходы на завершение проектирования, валидацию и изготовление первых образцов. При условии своевременной передачи дизайна на производство, первые кристаллы на базе 5-нм техпроцесса TSMC могут быть получены в начале 2026 года.
По расчётам компании, в случае успешной отладки, выход инженерных образцов и их тестирование займёт ещё несколько месяцев. В этом случае массовое производство может стартовать в начале 2027 года, а коммерческие поставки — в середине того же года. Это означает, что на реализацию проекта уйдёт почти 10 лет — изначально запуск был запланирован ещё на 2020 год.
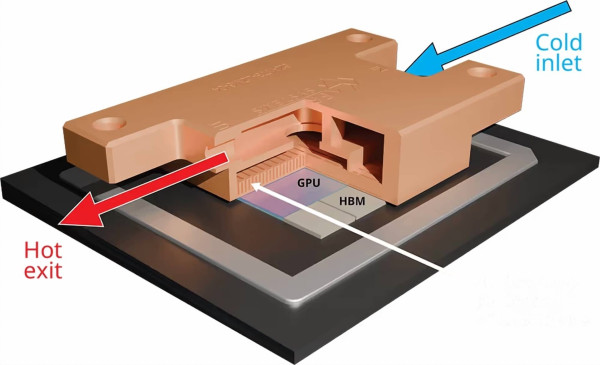
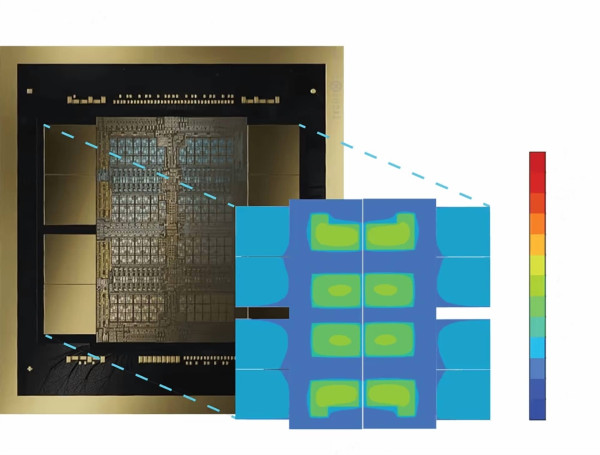
Компания Frore Systems представила новое жидкостное решение для серверных GPU, способное справляться с тепловыми нагрузками в десятки раз выше стандартных. Модель LiquidJet построена на основе 3D-структур коротких струй, созданных с использованием технологий полупроводникового производства. Эта архитектура заменяет классические 2D-микроканалы и обеспечивает целенаправленное охлаждение самых горячих зон GPU, таких как ядра и интерфейсы HBM.
По заявлению Frore, LiquidJet способна рассеивать до 600 Вт на квадратный сантиметр при входящей температуре 40 °C. Это более чем вдвое превышает возможности традиционных холодных пластин. Кроме того, новая система демонстрирует на 50 % более высокую эффективность охлаждения на литр потока и в 4 раза меньшую гидравлическую нагрузку, что снижает требования к помпам и энергопотребление всей системы.
Система полностью совместима с текущими стандартами холодных пластин и может масштабироваться под будущие архитектуры, включая NVIDIA Blackwell, Rubin и Feynman, где энергопотребление может превысить 4000 Вт на один чип. LiquidJet уже продемонстрировала способность работать с решениями мощностью 1400 Вт, такими как Blackwell Ultra, без падения частот и троттлинга при постоянной высокой нагрузке.
Важной особенностью является то, что производственный процесс LiquidJet допускает быструю адаптацию под любую топологию кристалла, включая специализированные ASIC-чипы, используемые гиперскейлерами и ИИ-облачными решениями. Это делает технологию универсальной основой для нового поколения серверного и датацентрового оборудования.
TSMC усиливает инвестиции в американское производство, готовясь к новому этапу расширения в Аризоне. На фоне рекордного спроса со стороны локальных клиентов компания подтверждает покупку второго промышленного участка, предназначенного для строительства дополнительных мощностей. Эти действия нацелены на то, чтобы ускорить перенос самых передовых техпроцессов на территорию США.
На текущий момент заводы TSMC в Аризоне выпускают чипы по 4-нм нормам, но в ближайшие годы планируется освоение 2-нм и более тонких узлов, включая потенциальный переход к 1.6 нм. В компании подчёркивают, что наращивание объёмов продиктовано долгосрочным ростом заказов, особенно в области ИИ. Именно с этим связано решение оперативно подготовить дополнительные площади под новое строительство и оставить задел под последующие расширения.
TSMC станет второй компанией в США, которая запустит 2-нм производство на своей площадке, укрепив позиции страны в сегменте продвинутой полупроводниковой продукции. Выход на этот уровень требует не только технической подготовки, но и логистической гибкости, которую обеспечивает присутствие вблизи ключевых партнёров. В случае успеха, разрыв между производством в Тайване и США существенно сократится.
По заявлению главы TSMC, американское направление теперь рассматривается как полноценный элемент глобальной стратегии, а не вспомогательная площадка. Увеличение мощностей станет ответом на давление со стороны крупнейших заказчиков, стремящихся локализовать цепочки поставок и минимизировать зависимость от внешних регионов.
Microsoft начала массовое внедрение искусственного интеллекта в Windows 11, добавив расширенные функции Copilot, не требующие нового оборудования. Пользователи получат доступ к голосовому управлению, визуальному анализу контента через Copilot Vision, а также новым возможностям действия ИИ от имени пользователя — включая работу с файлами, системными настройками и интернетом.
С помощью фразы "Hey Copilot" можно вызвать ИИ голосом, а затем использовать его для анализа экрана, поиска нужной информации, помощи в приложениях и даже просмотра видео с пояснениями. Эти функции работают на всех ПК с Windows 11 при ручной активации, без необходимости перехода на Copilot+.
Появился новый элемент панели задач — "Ask Copilot", заменяющий строку поиска. Он позволяет напрямую обратиться к ИИ и получить помощь в любом контексте. Также добавлена поддержка Copilot Connections — ИИ можно подключить к Gmail, Outlook, Google Drive и другим сервисам, чтобы управлять календарями, письмами и личными данными в защищённой среде.
Ещё одна важная функция — интеграция локального агента Manus в Проводник. Он способен выполнять задачи на основе локальных файлов — например, автоматически сгенерировать сайт или текст на основе документов пользователя. При этом ИИ может видеть экран и ориентироваться в контексте, подсказывая действия в режиме реального времени.
Большинство новшеств уже доступны участникам программы Windows Insider. Исключение — функция Click-to-Do для Zoom, которая требует ПК с Copilot+.
amsung представила новые подробности о своей памяти HBM4e, подтвердив, что чипы обеспечат скорость выше 13 Гбит/с на пин и совокупную пропускную способность до 3.25 ТБ/с — это почти в 2.5 раза выше, чем у HBM3e. Также компания заявила о двукратном снижении энергопотребления, до менее 1.95 пДж/бит, что делает HBM4e вдвое эффективнее предшественника.
По сообщениям отраслевых изданий, толчком к разработке стало требование NVIDIA, которая нуждается в более быстрой памяти для своего будущего ускорителя Vera Rubin. Хотя спецификации JEDEC для HBM4 ограничивают скорость на уровне 8 Гбит/с, Samsung, SK hynix и Micron уже работают над превышением 10 Гбит/с по пину. Для ускорения выпуска Samsung, по данным Chosun Daily, распустила внутреннюю группу по улучшению выхода 1c DRAM, несмотря на то, что текущая выходность HBM4e всё ещё ниже 50%. Компания пропустила стандартный внутренний аудит и перешла к активной подготовке массового производства.
По данным TrendForce, Samsung также перевела базовый кристалл HBM4 на техпроцесс 4 нм FinFET, что дает преимущество как в скорости, так и в масштабе производства. Старт массового производства чипов на 10 Гбит/с ожидается к концу 2025 года.
Кроме того, Samsung отчиталась о результатах 3 квартала 2025 года: операционная прибыль составила 12.1 трлн вон ($8.5 млрд) — на 32% больше, чем год назад, и значительно выше рыночных ожиданий. Аналитики считают, что подразделение DS (полупроводники) обеспечило около 5 трлн вон ($3.5 млрд) прибыли — это более чем в 10 раз выше показателей второго квартала. Главным драйвером стали успехи литейного бизнеса, где удалось увеличить загрузку мощностей и привлечь новых заказчиков. Полный отчет ожидается 30 октября.
Популярный фреймворк Ollama, предназначенный для локального запуска больших языковых моделей (LLM), вышел в новой тестовой версии 0.12.6-rc0. Главное нововведение — экспериментальная поддержка Vulkan API, которая давно находилась в разработке и теперь впервые стала доступна пользователям.
Ollama активно используется энтузиастами благодаря лёгкому запуску моделей Llama 3/4, Gemma, GPT-OSS, DeepSeek и других. Проект тесно интегрирован с Llama.cpp, обеспечивая высокую производительность и широкую поддержку библиотек и приложений. Однако до сих пор поддержка GPU была ограничена — для использования требовались ROCm, CUDA или SYCL. Благодаря внедрению Vulkan, запуск LLM теперь становится возможен на широком спектре GPU от AMD и Intel, для которых другие решения недоступны.
Поддержка Vulkan пока доступна только при сборке из исходного кода, и относится к числу экспериментальных функций. Разработчики подтверждают, что работают над устранением оставшихся ограничений и планируют добавить эту возможность в бинарные сборки Ollama в будущем.
Заявка на внедрение Vulkan велась уже полтора года, и сегодня она официально закрыта с выходом релиз-кандидата. Это важный шаг в сторону более широкой доступности Ollama на всех типах видеокарт, включая устаревшие и альтернативные GPU, где традиционные API недоступны.