Apple заключает соглашение с Google об использовании модифицированной версии AI-модели Gemini, содержащей 1,2 трлн параметров, чтобы поддержать обновлённую Siri в облаке. Эта модель значительно превосходит текущую облачную модель Siri, разработанную Apple, которая ограничена лишь 1,5 миллиардами параметров.
Компания провела тестирование ChatGPT от OpenAI и Claude от Anthropic, но в итоге остановилась на кастомизированной версии Gemini, способной обрабатывать сложные пользовательские запросы в рамках инфраструктуры Private Cloud Compute. Эта архитектура обеспечивает защиту приватности за счёт зашифрованных и не сохраняемых данных.
По данным Bloomberg, Apple ежегодно будет платить Google около $1 млрд за использование этой модели. Параллельно Google уже платит Apple порядка $20 млрд в год за статус поисковика по умолчанию в Safari и других сервисах компании. Внутренний проект Apple по улучшению Siri получил кодовое имя Glenwood и курируется Майком Рокуэллом (создатель Vision Pro) и Крейгом Федериги (глава софтверной инженерии).
Обновлённая Siri будет состоять из трёх ключевых компонентов:
Query planner — система планирования, определяющая способ выполнения команды: веб-поиск, доступ к личным данным или взаимодействие с приложениями через App Intents;
Knowledge search system — база знаний для ответов на стандартные вопросы без обращения к ChatGPT или вебу;
Summarizer — инструмент, использующий сторонние модели (включая ChatGPT), для создания сводок уведомлений, веб-страниц, заметок и т.п.
Gemini будет задействована для Query planner и Summarizer, тогда как модуль Knowledge останется за локальными LLM от Apple. Хотя Apple не планирует использовать Gemini вечно, на момент запуска Siri в iOS 26.4 именно эта модель станет основой для поддержки экранного и контекстного взаимодействия с голосовым помощником.
В сети появилось детальное сравнение стратегий выпуска графических драйверов тремя ведущими производителями — Nvidia, AMD и Intel — за 2025 год. Анализ, основанный на данных из официальных источников и баз данных, учитывал как WHQL-сертифицированные, так и опциональные/бета-версии драйверов, а также количество новых игр, получивших официальную поддержку "Game Ready".
Результаты демонстрируют явное лидерство компании Nvidia. За 2025 год она выпустила 21 WHQL-драйвер, обеспечив в них поддержку 54 новых игр. Эта цифра не включает мелкие исправления (Hotfix), которые обычно не добавляют оптимизации для новых проектов, а также обновления профилей через приложение Nvidia APP.
Компания Intel продемонстрировала агрессивную стратегию поддержки своих графических ускорителей. Хотя на официальном сайте можно отследить 7 WHQL-драйверов, более глубокий анализ баз данных показывает, что общее число релизов (включая WHQL и опциональные) обеспечило поддержку 50 новых игр.
AMD в этом сравнении оказалась на третьем месте. Согласно представленным данным, компания выпустила 6 WHQL-драйверов (поддержка 16 игр) и 8 бета-драйверов (поддержка 15 игр). Суммарно это составило 14 различных релизов и официальную поддержку 31 новой игры за год. В подсчет не включались обновления профилей, которые добавляются через программное обеспечение Adrenalin.
В сети появились новые подробности о структуре процессоров Panther Lake и Nova Lake, включая конфигурации ядер и целевые платформы. Согласно опубликованной информации, Intel активно развивает гибридную архитектуру с участием LP-E ядер, предназначенных для фоновых задач. Это решение распространяется как на мобильные, так и на десктопные чипы следующего поколения.
Наиболее распространённые конфигурации Panther Lake включают 4+8+4 и 4+8+4+12, где 4 — это P-ядра, 8 — E-ядра, 4 — LP-E ядра, а последняя цифра отражает количество блоков iGPU или NPU. Также упоминаются энергоэффективные модели 2+0+4+2 и 4+0+4+4, ориентированные на ультратонкие ноутбуки. При этом производительные модели Panther Lake H смогут достигать 5.1 ГГц, а общее значение производительности NPU+GPU+CPU превышает 180 TOPS, что вдвое выше текущих Meteor Lake.
Intel также отказывается от встроенного Bluetooth и Wi-Fi, полностью переходя на сетевые интерфейсы через PCIe, что требует обновления экосистемы. На графическом уровне Panther Lake получит 12-ядерный GPU на архитектуре Xe-LPG с двумя Render Slice и 16 МБ кеша L2. Младшие чипы (Wildcat Lake) ограничатся 2 МБ кеша.
Старшее поколение Nova Lake продвигает масштабирование: от 4+0+4+4 до 8+16+4+4, включая как энергоэффективные, так и флагманские решения. Это указывает на унифицированный подход к архитектуре с акцентом на масштабируемость и AI-ускорение. Также подтверждены варианты с 12 P-ядрами и степпинги A0, H0, C0 и B0 для Bartlett Lake-S.
Вьетнамский энтузиаст Нхенхофах из Modding Cafe представил уникальную версию ROG Astral GeForce RTX 5090/5080 с полностью скрытым водяным охлаждением, интегрированным прямо в конструкцию видеокарты. Этот кастомный проект сохраняет фирменный дизайн ASUS, но добавляет инновационную компоновку охлаждения, превращая GPU в автономную систему с радиатором, помпой и резервуаром.
Главная цель проекта — сохранить внешний вид видеокарты при полной замене системы охлаждения. В отличие от классических водоблоков, которые требуют снятия кожуха, новая система оставляет дизайн почти нетронутым. Трубки и фитинги полностью скрыты, все элементы охлаждения размещены внутри конструкции. Передняя панель содержит два акриловых окна резервуара и дисплей температуры, заменяя стандартные три вентилятора.
Хотя линейка ASUS ROG Astral LC уже включает версии с жидкостным охлаждением, они предполагают использование внешнего 360-мм радиатора, что делает их значительно крупнее. В отличие от этого решения, моддинг-проект предлагает полную интеграцию внутри самого GPU, сохраняя его компактность и визуальную целостность.
Пока не сообщается об эффективности новой системы, но ясно, что это концепт, созданный для выставочных целей, а не для массового рынка. Учитывая стоимость оригинальных моделей Astral, кастомная версия, вероятно, окажется вне потребительского сегмента по цене.
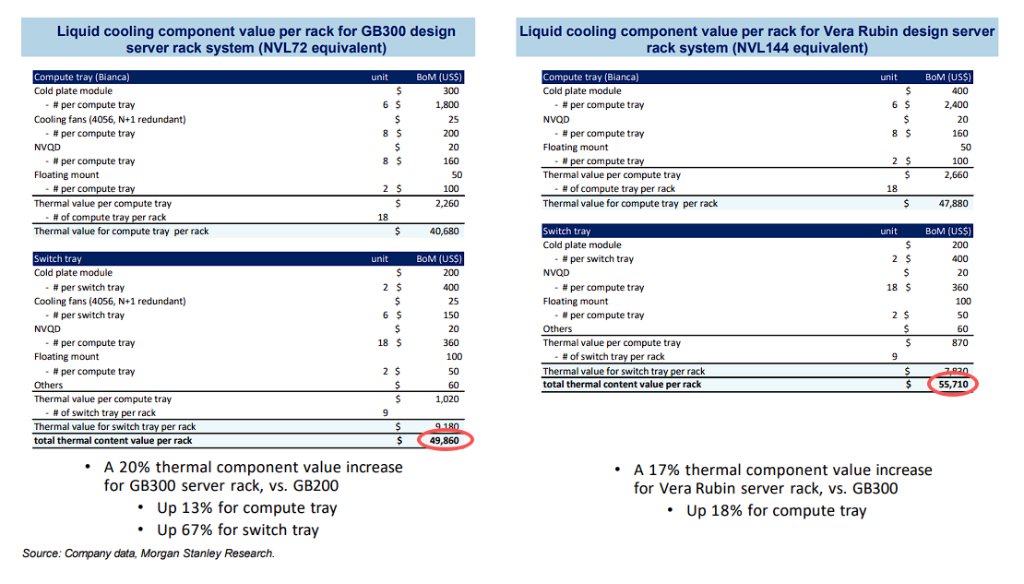
Аналитики из Morgan Stanley опубликовали отчет, в котором подробно разбирается стоимость компонентов жидкостного охлаждения для серверных стоек Nvidia. Согласно их данным, общая стоимость «термальных компонентов» для одной серверной стойки текущего поколения GB300 (NVL72) составляет $49,860. Эта цифра сама по себе уже включает 20% рост стоимости по сравнению с предыдущей платформой GB200.
Однако с выходом следующего поколения ИИ-ускорителей тенденция к удорожанию сохранится. По прогнозам, для платформы Vera Rubin (NVL144) общая стоимость... $55,710 за одну стойку. Это представляет собой дополнительный 17% рост по сравнению с GB300.
Основным драйвером удорожания станут вычислительные лотки (compute tray). В отчете указано, что стоимость охлаждения для 18 таких лотков в стойке Vera Rubin вырастет до $47,880 (по $2,660 за лоток) по сравнению с $40,680 (по $2,260 за лоток) в поколении GB300. Это составляет 18% рост именно в этой категории.
Любопытно, что стоимость компонентов охлаждения для коммутационных лотков (switch tray) при этом, наоборот, снизится. Согласно таблице, общая стоимость для 9 лотков-коммутаторов в стойке Vera Rubin составит $7,830 ($870 за лоток), что заметно меньше по сравнению с $9,180 ($1,020 за лоток) в системе GB300.
В состав компонентов охлаждения, учтенных в отчете, входят холодные пластины (cold plate modules), вентиляторы, компоненты NVQD и различные монтажные крепления. Рост общей стоимости подчеркивает растущую сложность управления тепловыделением в будущих поколениях ИИ-ускорителей, которые требуют все более дорогих инженерных решений.
MSI представила свою новую флагманскую материнскую плату MEG X870E ACE MAX для платформы AM5, которая станет самой мощной в линейке ATX-формата. Эта модель относится к топовому классу ACE, ранее представленному на платформах X670E и Z890, и сочетает в себе продвинутые функции для энтузиастов разгона, улучшенную BIOS и премиальный дизайн.
Среди ключевых особенностей — схема питания 18+2+1 с 110-амперными фазами, двойной 8-контактный разъём питания CPU, а также фирменный OC Engine — встроенный генератор тактов, позволяющий добиться до 15% прироста производительности. Дополнительно реализован Direct OC Jumper для моментальной настройки BCLK в реальном времени.
Новая BIOS ёмкостью 64 МБ обеспечит поддержку будущих обновлений UEFI, включая линейку AMD Ryzen 3D V-Cache нового поколения, среди которых ожидаются модели с двойными CCD. Также заявлена система Illusion Lightning с уникальной подсветкой на передней панели и логотипом MSI Dragon.
На плате размещены пять слотов M.2, из которых два — с поддержкой PCIe 5.0, и все они охлаждаются системой Shield Frozr с магнитным креплением или быстрой клипсой. Верхний слот PCIe 5.0 x16 использует EZ PCIe Release для облегчения замены GPU. Система охлаждения построена на прямом контакте с тепловой трубкой и пластинами с волнообразными рёбрами, с применением термопрокладок 9 Вт/м·К и металлической задней панели.
Плата также предлагает 10GbE-сеть, поддержку Wi-Fi 7, порты USB 40G, дополнительный 8-контактный разъём для питания PCIe и двойные PCIe 5.0 x16 слоты. Официальный старт продаж ожидается ближе к CES 2026, а первые поставки уже начались в линейке X870/X870E.
Компания 3mdeb, специализирующаяся на открытом микропрограммном обеспечении, завершает масштабный проект по адаптации Coreboot и библиотеки инициализации AMD openSIL для серверной материнской платы Gigabyte MZ33-AR1. Эта плата совместима с последним поколением процессоров AMD EPYC 9005 “Turin” и доступна для массового использования, что делает её отличной платформой для демонстрации открытых прошивок.
Проект реализуется при финансовой поддержке фонда NLnet, цель которого — продвигать открытые технологии. Команда 3mdeb во главе с Михалом Жиговским выбрала MZ33-AR1 в качестве основной целевой платформы и уже добилась устойчивой загрузки как Microsoft Windows, так и Linux, завершив настройку ACPI и исправление множества ошибок. Ранее 3mdeb уже адаптировали Coreboot к настольным платам на базе Intel, а теперь сфокусировались на серверных решениях AMD.
В блоге компании подчёркивается, что без инициативы AMD openSIL реализация поддержки новой серверной микроархитектуры была бы невозможна. Проект стал важным шагом в развитии открытых прошивок для серверных платформ AMD, особенно с учётом того, что openSIL ориентирован на будущие решения на базе Zen 6.
Успешная реализация порта Coreboot+openSIL на Gigabyte MZ33-AR1 может стать отправной точкой для расширения поддержки открытых прошивок на другие современные платформы AMD, как серверные, так и клиентские.
Инженеры из Калифорнийского университета в Сан-Диего разработали принципиально новую технологию охлаждения, которая может решить проблему растущего энергопотребления ИИ-центров обработки данных. Системы охлаждения серверов являются одними из самых «прожорливых» компонентов в ЦОД, и новая разработка, использующая специально разработанную волоконную мембрану, обещает значительно снизить потребление энергии и воды.
Технология основана на принципе испарительного охлаждения. Мембрана состоит из множества взаимосвязанных микроскопических пор, которые втягивают охлаждающую жидкость за счет капиллярного действия. Система имеет трехслойную структуру: нижний слой с микроканалами для жидкости, средний слой с самой мембраной и верхний слой-испаритель. Тепло, выделяемое ИИ-ускорителем, превращает жидкость в пар, который затем эффективно уходит через верхний слой.
Этот дизайн решает ключевые проблемы предыдущих попыток испарительного охлаждения. Ранее в подобных конструкциях поры были либо слишком малы, что приводило к засорению, либо слишком велики, что вызывало нежелательное кипение теплоносителя. Новая мембрана имеет поры "идеального" размера, что предотвращает обе проблемы и обеспечивает стабильную работу.
В ходе тестов система продемонстрировала рекордный показатель теплового потока в 800 Вт на квадратный сантиметр и сохраняла полную стабильность в течение нескольких часов работы. Это делает ее чрезвычайно мощным решением для будущих поколений ИИ-ускорителей, чье энергопотребление продолжает стремительно расти.
Компания AMD представила финансовые результаты за третий квартал 2025 года, продемонстрировав значительный рост в своем ключевом сегменте Client and Gaming. Общая выручка подразделения достигла $4.0 миллиарда, что на 73% превышает показатель аналогичного периода прошлого года, составлявший $2.3 миллиарда.
Существенно выросла и прибыльность. Операционная прибыль... $867 миллионов, в то время как год назад этот показатель составлял всего $288 миллионов. Операционная маржа увеличилась с 12% до 21%, что свидетельствует о высокой эффективности бизнеса.
Рост выручки был обеспечен обоими направлениями. Клиентский сегмент (процессоры) вырос с $1.8 млрд до $2.8 млрд. В отчете это объясняется рекордными продажами процессоров Ryzen.
Игровой сегмент (видеокарты и полузаказные решения) показал еще более взрывной рост, увеличив выручку с $0.5 млрд до $1.3 млрд. Компания официально заявляет, что это обусловлено ростом доходов от полузаказных продуктов (чипов для консолей) и сильным спросом на игровые графические процессоры Radeon.
Среди других стратегических достижений квартала компания отметила запуск новых процессоров Ryzen Threadripper 9000WX и 9000X, хорошие мировые продажи портативных ПК на базе Ryzen Z2 (таких как ROG Ally Ally X), а также быстрое внедрение технологии AMD FSR 4, которая была добавлена в более чем 85 игр.
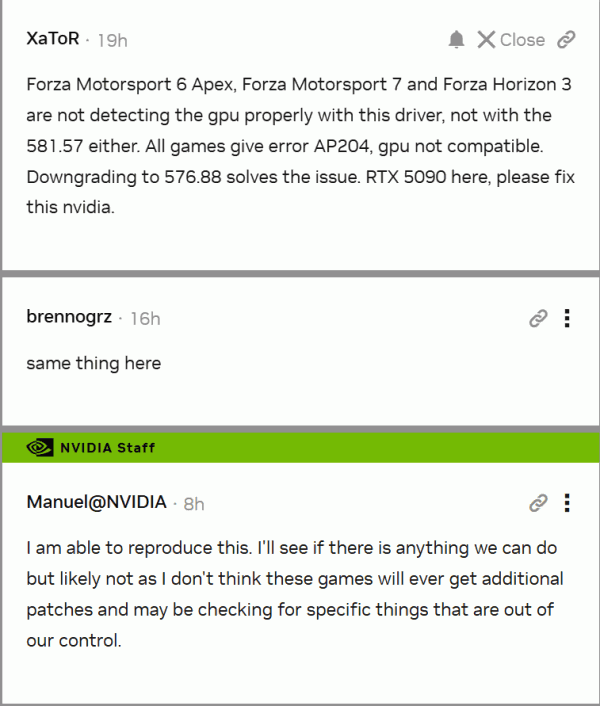
Пользователи видеокарт NVIDIA RTX 5090 столкнулись с серьёзной проблемой при запуске игр Forza Motorsport 6 Apex, Forza Motorsport 7 и Forza Horizon 3. После установки драйвера GeForce 581.57 (и более раннего 581.47) игры выдают ошибку AP204 (GPU not compatible), не распознавая видеокарту. Ошибка делает запуск невозможным.
Как отметил один из пользователей, понижение драйвера до версии 576.88 полностью решает проблему, подтверждая, что речь идёт именно о несовместимости новых драйверов с устаревшими играми. Второй пользователь подтвердил аналогичную ситуацию, а представитель NVIDIA, Manuel Guzman, сообщил, что ситуация воспроизводится в лабораторных условиях и уже проверяется внутри компании.
Однако есть важная оговорка: по словам представителя NVIDIA, маловероятно, что можно будет исправить эту ошибку на уровне драйвера. Причина в том, что данные игры больше не получают патчи, а система проверки GPU в них, скорее всего, жёстко привязана к старым ID видеокарт, не включающим новые модели. Это создаёт проблему совместимости, которую невозможно решить без участия разработчиков игр — а такие патчи уже не ожидаются.
Таким образом, владельцы RTX 5090 и новых драйверов могут остаться без доступа к ряду классических тайтлов серии Forza, если не использовать старые версии драйверов. Временное решение — даунгрейд до 576.88, но оно сопряжено с риском потери поддержки новых игр и исправлений.