NVIDIA впервые публично показала системную плату Vera Rubin Superchip, предназначенную для вычислений нового поколения. На мероприятии GTC в Вашингтоне был продемонстрирован рабочий образец с 88-ядерным CPU Vera и двумя GPU Rubin, каждый из которых оснащён 8 чипами HBM4 и двумя кристаллами Reticle Size. Система поддерживает до 2 ТБ быстрой памяти, включая LPDDR и HBM4, а соединение CPU и GPU реализовано через NVLINK-C2C со скоростью до 1.8 ТБ/с.
Платформа Rubin NVL144 выйдет во второй половине 2026 года. Она обеспечит 50 PFLOPS FP4 на узел, 3.6 Exaflops FP4 в кластере и 1.2 Exaflops FP8, что на 3.3 раза выше, чем GB300 NVL72. Поддержка 13 ТБ/с пропускной способности HBM4, общая ёмкость памяти — 75 ТБ. CPU Vera выполнен на кастомной архитектуре Arm с 88 ядрами и 176 потоками.
В 2027 году выйдет флагманская система Rubin Ultra NVL576. Здесь масштаб увеличен в 4 раза: четыре GPU-чипа Rubin Ultra с 16 чипами HBM4e, до 100 PFLOPS на узел, 15 Exaflops FP4 и 5 Exaflops FP8 в кластере, 1 ТБ HBM4e на узел и 365 ТБ общей памяти. NVLINK и CX-интерфейсы обеспечат 1.5 ПБ/с и 115.2 ТБ/с соответственно.
Также подтверждён план по запуску в 2028 году нового поколения под кодовым именем Feynman с BlueField-5, Spectrum7 и CPU Vera, поддержкой следующей версии NVLink и CX10. Это позволит NVIDIA сохранять годовой ритм развития и превосходство в области ИИ-вычислений.
На рынке DRAM нарастает кризис — мировые гиперскейлеры получают лишь 70% заказанных объёмов серверной памяти, несмотря на согласованные повышения контрактных цен до 50% в четвёртом квартале. Эти цифры существенно превышают заложенные ранее бюджеты в 30%, что усугубляет ситуацию для всех участников цепочки поставок.
Основной фактор давления — бурный рост спроса со стороны ИИ-сектора. Хотя на слуху в первую очередь HBM, дефицит также охватил обычные DDR5 RDIMM, особенно на продвинутых техпроцессах. Крупнейшие производители, такие как Samsung и SK hynix, активно перераспределяют производственные мощности под нужды ИИ-ускорителей. Samsung уже поднял цены на RDIMM до 50%, а на серверные SSD — до 35%.
Ситуация на спотовом рынке ухудшается с конца сентября: цены на DDR5 16 ГБ модули выросли с $7–8 до $13, а поставки на ноябрь ещё сильнее ограничены. Модульные сборщики уже готовятся к полному отсутствию запасов к концу квартала.
При этом мелкие OEM и дистрибьюторы получают лишь 35–40% от запрошенных объёмов, поскольку гиперскейлеры выкупают фиксированные квоты. Остальным остаётся только спотовый рынок или ожидание до 2026 года. Компания Micron предупредила, что рост поставок не поспевает за спросом, и такая ситуация сохранится до конца следующего года.
DDR4 теряет позиции: китайская Nanya заявила, что теперь этот стандарт занимает лишь 20% от общего объёма рынка, и его производство больше не приоритетно. Без резкого улучшения выхода годных чипов или ослабления спроса, рынок столкнётся с жёстким распределением DRAM вплоть до 2026 года.
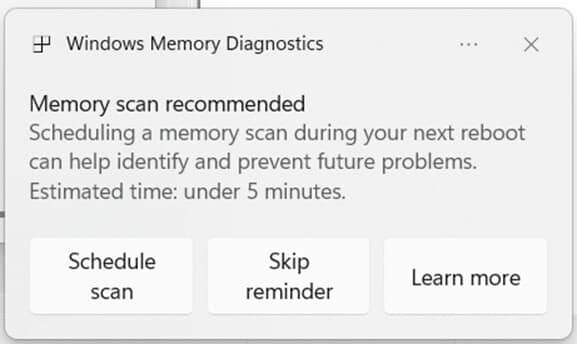
Microsoft внедрила важную функцию в Windows 11, которая может серьёзно повысить стабильность системы. Теперь после "синего экрана смерти" (BSOD) пользователи будут получать уведомление с предложением запустить диагностику оперативной памяти. Эта возможность впервые появилась в Windows 11 Insider Preview Build 26220.6982 и 26120.6982, и пока доступна участникам Dev и Beta каналов.
После неожиданной перезагрузки система покажет уведомление при входе в Windows, предлагая выполнить быструю проверку памяти. Если пользователь согласится, будет запланирован запуск Windows Memory Diagnostic при следующем включении ПК. В среднем процесс занимает менее пяти минут, после чего система продолжит загрузку в обычном режиме. В случае выявления и устранения ошибок в памяти пользователь получит об этом уведомление после перезагрузки.
На начальном этапе Microsoft собирает статистику и отмечает каждый BSOD, чтобы выявить, насколько часто неполадки с ОЗУ вызывают сбои. В будущем планируется уточнить механизм срабатывания функции, чтобы исключить ложные срабатывания и повысить точность диагностики. При этом новая система не работает на Arm64, при включённой защите администратора или BitLocker без Secure Boot.
Команда RPCS3 — самого продвинутого эмулятора PlayStation 3 — обновила рекомендованные системные требования к видеокартам. Обновление отражает изменения в поддержке драйверов от AMD и NVIDIA, а также подчёркивает текущее состояние дел с Intel.
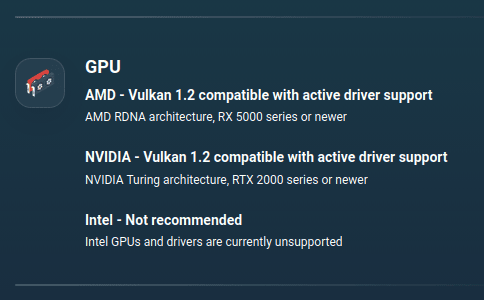
Теперь рекомендуются только GPU с поддержкой Vulkan 1.2 и актуальными драйверами:
AMD: минимум архитектура RDNA, то есть серия RX 5000 или новее. Старые карты Polaris (RX 400/500) больше не входят в список.
NVIDIA: минимально — архитектура Turing, начиная с серии RTX 2000. Это исключает старые GTX 900 и GTX 10xx.
Intel: официально указано как не рекомендуется — драйверы и GPU не обеспечивают стабильной или полной поддержки, даже с Vulkan.
Причиной пересмотра стала остановка выпуска новых драйверов для Polaris и Maxwell, а значит — прекращение устранения багов, оптимизаций и совместимости с новыми функциями Vulkan. Команда RPCS3 делает акцент на поддержке стабильной и актуальной графической среды, чтобы избежать проблем с эмуляцией и графическими артефактами.
Это обновление может повлиять на пользователей с более старыми картами, особенно тех, кто использовал RX 580 или GTX 1070 — ранее они были допустимыми. Теперь для комфортной и стабильной эмуляции рекомендуется переход на современные GPU с актуальной архитектурой и драйверами.
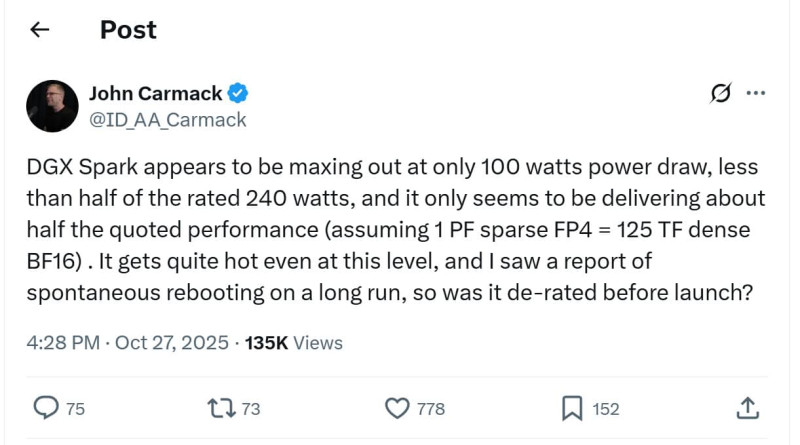
Компактный AI-компьютер NVIDIA DGX Spark, представленный как локальное решение для разработки и отладки ИИ-моделей, не оправдывает заявленных характеристик. По словам Джона Кармака, основателя Keen Technologies и бывшего технического директора Oculus, фактическое энергопотребление устройства составляет всего 100 Вт вместо обещанных 240 Вт, что указывает на падение производительности почти вдвое.
Согласно спецификациям, DGX Spark должен обеспечивать до 125 TFLOPS при вычислениях в BF16 и около 1000 TOPS в формате NVFP4, однако реальные замеры демонстрируют только 60 TFLOPS в BF16 и 480 TFLOPS в FP4, что соответствует лишь половине ожидаемых значений. Предположительно, заниженная производительность связана с снижением тактовых частот и троттлингом из-за перегрева, а в некоторых случаях сообщается даже о перезагрузке системы. Устройство основано на гибридном чипе, сочетающем CPU от MediaTek на архитектуре Arm v9.2 (20 ядер) и GPU на архитектуре Blackwell, выполненном по техпроцессу 3 нм от TSMC.
DGX Spark оснащён 128 ГБ LPDDR5X-9400, что при 256-битной шине памяти даёт пропускную способность около 301 ГБ/с, а также сетевой картой ConnectX-7 через PCIe 5.0 x8. Все высокоскоростные интерфейсы сконцентрированы на CPU-матрице, включая NVMe и внешние устройства.
Ещё одной возможной причиной расхождений является использование структурной разреженности в расчётах FP4 — при её отключении производительность заметно падает. Учитывая цену в $3999, вопросы к стабильности и мощности устройства становятся критичными. Не исключено, что будущие обновления прошивки или альтернативное охлаждение смогут исправить ситуацию, но на текущий момент устройство показывает далеко не заявленный уровень.
AMD официально запускает Radeon AI PRO R9700 — новую видеокарту на базе RDNA4, ориентированную на ИИ-нагрузки. При цене от $1299, она предлагает 32 ГБ GDDR6, 128 AI-ускорителей и пиковую производительность до 96 TFLOPs (FP16) и 1531 TOPS (INT4 sparse) при TDP 300 Вт.
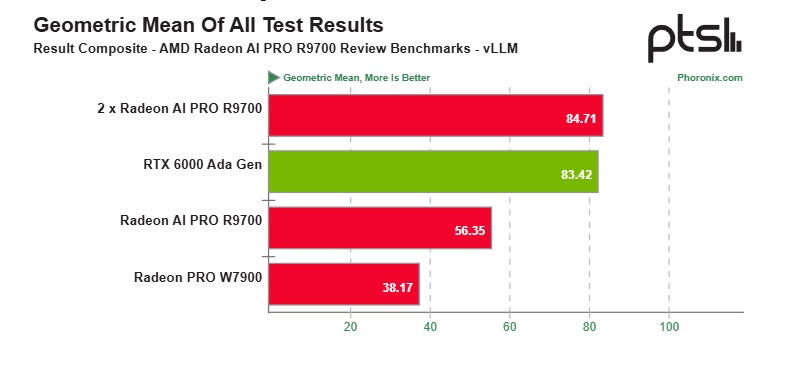
В тестах под Linux с ROCm 7.0 модель R9700 обошла Radeon PRO W7900 на 47%, а в конфигурации с двумя картами смогла небольшим отрывом опередить RTX 6000 Ada Generation в сводном показателе производительности vLLM. Суммарные 64 ГБ памяти против 48 ГБ у RTX, почти идентичная мощность и цена вдвое ниже — R9700 вдвойне эффективна по соотношению цена/результат, особенно при сохранении заявленной цены.
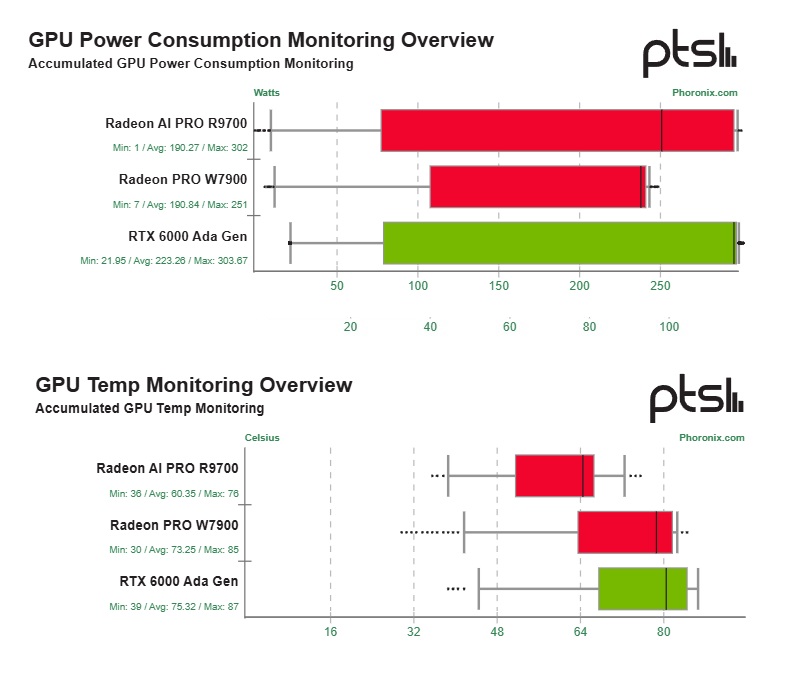
Что касается энергопотребления, средний показатель R9700 составил 190 Вт против 223 Вт у RTX 6000 Ada, при одинаковом пике в 300 Вт. Температурно R9700 также лидирует: при среднем значении 60.35°C она ощутимо холоднее RTX (75.32°C) и W7900 (73.25°C).
AMD явно делает ставку на открытость — карта отлично работает с open-source Linux-драйверами, и ROCm 7.0 уже поддерживает её "из коробки". Пока NVIDIA RTX PRO Blackwell остаётся недоступной для тестов, Radeon AI PRO R9700 показывает впечатляющую мощь и ценовую конкурентоспособность на фоне лидеров.
AMD запускает видеокарту Radeon AI PRO R9700 для розничной продажи — спустя три месяца после выхода в составе готовых рабочих станций. Это профессиональная модель на архитектуре RDNA4 с 32 ГБ видеопамяти, ранее доступная только для корпоративных клиентов и сборщиков систем.
В основе карты лежит чип Navi 48 с 4096 потоковыми процессорами, такой же, как у игровой Radeon RX 9070 XT. Однако в отличие от неё, PRO-модель вдвое увеличивает объём памяти и не имеет разгона. Энергопотребление — 300 Вт, против 304 Вт у RX-версии. Все видеокарты оснащены новым 16-контактным разъёмом 12V-2×6, с переходником в комплекте — старые 8-pin больше не используются.
Radeon AI PRO R9700 сохраняет турбинное двухслотовое охлаждение, но AMD разрешила партнёрам слегка модифицировать внешний вид. Так, Gigabyte выпустит серебристую версию, а ASRock предложит вариант под брендом Creator. Внутреннее устройство и PCB у всех моделей идентичны. В продаже уже заявлены версии по цене $1299, что в два раза дороже RX 9070 XT, которую в магазинах можно найти за $600–700.
Новинка позиционируется не как игровая карта, а как решение для задач ИИ, 3D-визуализации, научных расчётов и работы с большими объёмами данных. Несмотря на архитектурную схожесть с игровыми моделями, PRO R9700 полностью ориентирована на профессиональное использование.
Министерство энергетики США заключило партнёрство с AMD для создания двух новых суперкомпьютеров — Lux и Discovery, которые будут использовать новейшие AI-чипы Instinct MI355X и MI430. Эти проекты станут важным шагом в направлении расширения научных вычислений и укрепят позиции AMD в конкуренции с NVIDIA на рынке ИИ-оборудования для HPC.
Согласно данным Reuters, первая система под названием Lux будет введена в эксплуатацию уже в течение шести месяцев. В ней будут задействованы MI355X и инфраструктура от таких партнёров, как Hewlett Packard, Oracle и Национальная лаборатория Ок-Ридж. Генеральный директор AMD Лиза Су подчеркнула рекордные сроки развёртывания проекта.
Вторая система — Discovery — будет запущена до 2028 года и использует новый кастомный чип MI430, созданный специально под задачи высокопроизводительных вычислений. Этот проект обсуждался Министерством с прошлого года, и теперь AMD официально выбрана основным поставщиком вычислительных решений.
Общий бюджет программ приближается к $1 миллиарду, при этом Минэнерго активно ищет дополнительные частные партнёрства для масштабирования вычислительных мощностей. Отмечается, что выбор AMD может быть обусловлен успешным опытом с суперкомпьютером Frontier, который уже эксплуатируется DoE и построен также на решениях AMD.
Хотя в будущем ожидается расширение сотрудничества с другими вендорами, включая NVIDIA, сейчас именно AMD получает преимущество благодаря полной интеграции с экосистемой DoE и ускоренному циклу поставок.
MSI официально представила видеокарту GeForce RTX 5050 8G INSPIRE ITX OC (модель G5050-8IIC), ориентированную на сборки малого формата. Устройство построено на архитектуре NVIDIA Blackwell, поддерживает DLSS 4 с генерацией кадров и подходит как для игр, так и для работы с ИИ-приложениями и мультимедиа.
RTX 5050 ITX использует графический процессор NVIDIA GeForce RTX 5050, работает через интерфейс PCI Express Gen 5 x16 (физически использует x8) и оснащена 8 ГБ памяти GDDR6 с пропускной способностью 20 Гбит/с. Заявленная Boost-частота составляет 2602 МГц, а через утилиту MSI Center можно активировать экстремальный режим до 2617 МГц.
Охлаждение реализовано с помощью TORX Fan 5.0, радиатора с тепловыми трубками и технологии Zero Frozr, обеспечивающей полную остановку вентиляторов при низкой нагрузке. Дополнительную жёсткость и терморегуляцию обеспечивает металлическая усилительная пластина.
Видеокарта занимает один слот и имеет размеры 147 × 120 × 45 мм. Питание осуществляется через один 8-контактный разъём, потребление составляет 130 Вт, а рекомендованный блок питания — не менее 550 Вт. Поддерживаются DisplayPort 2.1b (3 шт.) и HDMI 2.1b (1 шт.), включая вывод до 8K 120 Гц с DSC, VRR и HDR.
Карта также поддерживает NVIDIA Reflex, G-SYNC, Broadcast, NVIDIA ACE, DirectX 12 Ultimate, OpenGL 4.6, вывод изображения на до 4 дисплеев и максимальное цифровое разрешение до 7680×4320. Вес карты составляет 551 г (869 г с упаковкой).
Qualcomm Technologies анонсировала AI200 и AI250 — специализированные решения для инференса генеративного ИИ в дата-центрах, обеспечивающие рекордную производительность на уровне стойки (rack-scale) при минимальной совокупной стоимости владения (TCO). Новые ускорители нацелены на крупные модели — LLM и LMM, предлагая сочетание масштабируемости, энергоэффективности и высокой пропускной способности памяти.
Qualcomm AI200 представляет собой готовую rack-level платформу, оптимизированную для инференса моделей и мультимодальных систем. Каждая карта оснащена 768 ГБ LPDDR-памяти, что обеспечивает высокий объём при низкой себестоимости. Решение ориентировано на предприятия, которым требуется стабильная производительность при низком энергопотреблении и гибкой масштабируемости.
AI250 использует инновационную архитектуру ближней памяти (near-memory computing), обеспечивая более чем 10-кратный рост эффективной пропускной способности и значительное снижение энергопотребления. Такая конструкция позволяет разделять вычислительные и памятьные ресурсы, достигая лучшего соотношения производительности и стоимости.
Обе платформы поддерживают жидкостное охлаждение, PCIe для масштабирования вглубь и Ethernet для масштабирования вширь, а также технологии конфиденциальных вычислений для безопасной работы ИИ. Суммарное энергопотребление одной стойки достигает 160 кВт.
Программная экосистема Qualcomm включает полный стек от прикладного уровня до системного, поддерживая ведущие ML- и LLM-фреймворки, а также библиотеку Efficient Transformers и AI Inference Suite. Разработчики получают доступ к автоматической интеграции моделей Hugging Face и «одно-кликовому» деплою, что упрощает внедрение уже обученных моделей.
AI200 поступит в коммерческое производство в 2026 году, а AI250 — в 2027-м. Qualcomm заявила о планах придерживаться годового цикла обновлений, ориентируясь на высокую энергоэффективность и лидирующее TCO в индустрии.