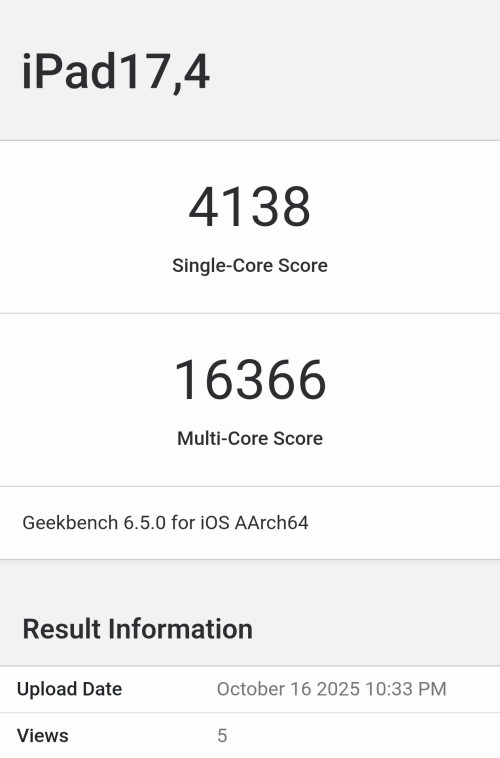
Свежие результаты Geekbench 6.5 подтверждают, что 10-ядерный чип Apple M5 демонстрирует разные показатели в зависимости от устройства. В iPad Pro M5 (iPad17,4) частота CPU составляет 4.43 ГГц, а однопоточная и многопоточная производительность достигают 4138 и 16366 баллов соответственно.
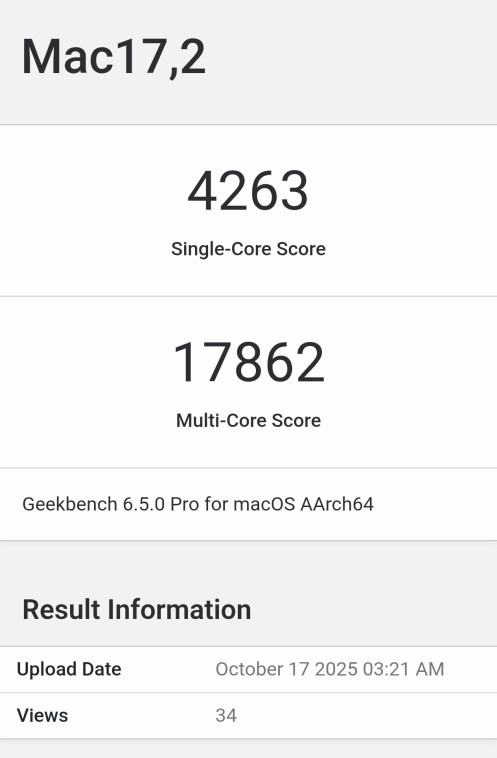
В то же время, MacBook Pro M5 (Mac17,2) работает на более высокой частоте 4.61 ГГц и показывает 4263 в ST и 17862 в MT, что даёт ноутбуку заметное преимущество. Архитектура обоих чипов идентична: 4 производительных и 6 энергоэффективных ядер, 6 МБ L2-кэша и тот же набор инструкций.
Оба устройства используют одну и ту же версию чипа, но планшет работает с более мягким температурным и энергопрофилем, в то время как ноутбук позволяет раскрыть потенциал M5 на максимальной частоте. Это доказывает, что Apple адаптирует один и тот же чип под разные форм-факторы, предлагая баланс между мощностью и автономностью.
Компания Maxsun анонсировала новую материнскую плату Terminator B850 BKB, в которой реализован задний слот под видеокарту, исключающий необходимость использования райзер-кабелей. Это решение направлено на повышение стабильности сигнала и улучшение охлаждения при вертикальном расположении GPU.
Новинка оснащена разъёмом PCIe 5.0 x16, который установлен на обратной стороне платы, что позволяет напрямую монтировать видеокарту вертикально без удлинителей. Такая компоновка минимизирует помехи в передаче сигнала и способствует улучшенному воздушному потоку внутри корпуса, что особенно важно для производительных систем с мощной графикой.
Макет рассчитан на современные сборки с прицелом на энтузиастов и креаторов. Благодаря отказу от дополнительного оборудования, как райзер-кабели, сборка становится не только чище визуально, но и технически надёжнее. Это также освобождает больше пространства в корпусе и снижает риск перегрева в зоне GPU.
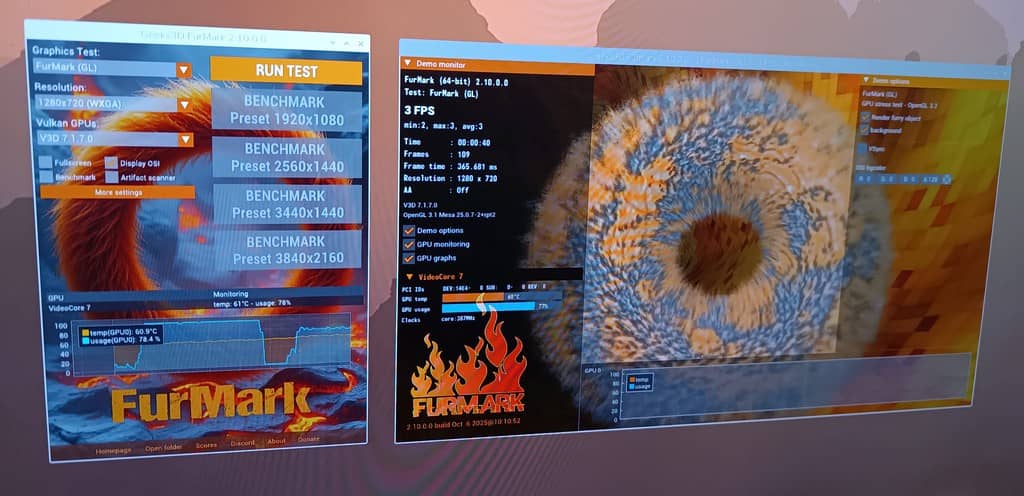
FurMark 2.10.0 представлен как обновлённая версия популярного GPU-бенчмарка и стресс-теста, доступного для Windows и Linux. Новая сборка включает важные улучшения, включая поддержку новых видеокарт, дополнительные VRAM-тесты и новый пресет для ультрашироких мониторов.
В версии 2.10 добавлена поддержка таких моделей, как AMD Radeon RX 9060, RX 7700, RX 7400, Radeon PRO W7400, а также NVIDIA GeForce RTX 5090 D v2 и Intel Arc Pro B50 / B60. Также добавлены имена AIB-версий, включая ASUS RTX 5080 Noctua OC, MSI RTX 5080 Expert OC, RTX 5060 Gaming OC, GIGABYTE RTX 5050 Gaming OC и Zotac RTX 5070 SOLID. Все эти GPU теперь корректно отображаются и тестируются в FurMark 2.
Существенным нововведением стало появление нового пресета 3440×1440 (UWQHD) — теперь он доступен в виде параметра командной строки --p3440x1440. Для тестирования видеопамяти добавлены режимы на 10 и 32 ГБ VRAM, что особенно актуально для современных графических адаптеров с большим объёмом памяти. В Linux-версии значительно улучшена поддержка GPU Intel Arc с Xe-драйверами и ядром 6.16+.
Кроме того, теперь FurMark 2 работает на Raspberry Pi 5, предоставляя базовый мониторинг графического ядра. Интерфейс обновлённой утилиты также получил улучшения, включая интеграцию GPU-Z 2.68, GPU Shark2 2.10 и библиотек GeeXLab 0.66.
ASUS ProArt Display PA32KCX — первый в мире профессиональный 8K HDR монитор с mini LED-подсветкой, предлагающий 4032 зоны локального затемнения, яркость до 1200 нит и устойчивую яркость 1000 нит на весь экран. Панель IPS с разрешением 7680×4320 обеспечивает плотность 275 пикселей на дюйм, что даёт до 300% больше рабочего пространства по сравнению с 4K. Устройство охватывает 95% Adobe RGB и 97% DCI-P3, обеспечивает точность цветопередачи Delta E<1 и поддерживает HDR10, HLG и Dolby Vision.
Монитор оснащён встроенным моторизованным колориметром для автокалибровки, а также фирменным ПО ProArt Calibration с поддержкой Calman и ColourSpace CMS. Калибровка возможна по расписанию, результаты сохраняются во внутреннюю память монитора, что упрощает работу с разными системами.
Среди дополнительных возможностей — две порта Thunderbolt 4, DisplayPort 2.1, HDMI 2.1, встроенный Auto KVM, режимы PbP и PiP, а также датчики освещения и присутствия. Стенд монитора поддерживает регулировки по наклону, высоте и повороту, а в комплект входит экранный кожух для снижения бликов.
Каждая покупка ProArt PA32KCX в ряде регионов даёт бесплатную подписку на Adobe Creative Cloud сроком на 3 месяца, включая Substance 3D и Acrobat. Период активации — до 31 августа 2026 года.
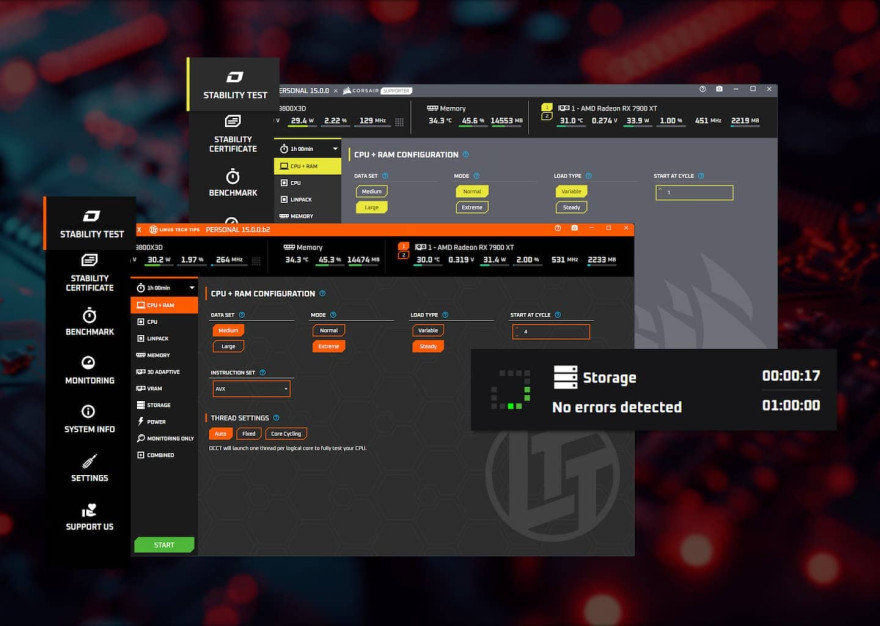
OCCT v15 официально вышла из стадии бета и теперь доступна всем пользователям, включая версии Pro и Enterprise. Одним из ключевых нововведений стал стабильный Storage Test, предназначенный для стресс-тестирования SSD и HDD в условиях высоких температур и нагрузок. Также представлена новая Storage Benchmark, основанная на метриках, аналогичных CrystalDiskMark, что делает результаты максимально понятными и удобными для сравнения.
Помимо этого, серьёзные изменения коснулись 3D Adaptive Test, который теперь стал точнее и требовательнее, с улучшенным механизмом определения ошибок. В некоторых случаях тест может провоцировать ограничение частот и энергопотребления на GPU, чтобы выявлять проблемы максимально эффективно. Также появился экспериментальный инструмент определения писка дросселей (Coil Whine Detection), позволяющий «услышать» поведение GPU под разной нагрузкой.
Наконец, в OCCT вернулась поддержка пользовательских скинов. В версии 15 уже доступны стили от LinusTechTips и Corsair, которые можно активировать через настройки программы. OCCT теперь всё ближе к роли универсального инструмента для оверклокеров и профессионалов, заменяя сразу несколько приложений.
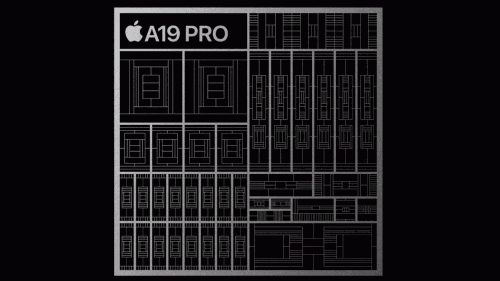
Apple сделала очередной шаг к унификации своей экосистемы: A19 Pro, новый чип для iPhone, всё больше напоминает по архитектуре M5, используемый в Mac. Несмотря на разницу в позиционировании — смартфон против настольного устройства — оба процессора построены на единой технологической платформе, отличаясь лишь масштабом.
В CPU-составе M5 представлен 10‑ядерный блок (4 быстрых + 6 энергоэффективных), тогда как A19 Pro ограничился 6 ядрами (2 производительных и 4 энергоэффективных). Однако архитектура ядер остается идентичной. В графической части оба чипа применяют дизайн с нейроускорителем в каждом ядре и поддержкой трассировки лучей: у M5 — 10 графических ядер, у A19 Pro — 6.
Они также используют 16-ядерный Neural Engine, что дает одинаковые возможности ускорения задач машинного обучения. Разница проявляется в пропускной способности памяти: у M5 она достигает 153 ГБ/с (16 ГБ LPDDR5X), у A19 Pro — 75,8 ГБ/с (12 ГБ LPDDR5X), хотя частота памяти одинакова — 9600 MT/s.
По сути, A19 Pro — это уменьшенный M5, адаптированный под смартфонные задачи. Это направление конвергенции архитектур значительно упрощает разработку софта и объединяет экосистему.
Компания Microsoft раскрыла планы по развитию Xbox Ally — портативной консоли, разработанной совместно с ASUS ROG. Уже в ближайшие недели появится первое крупное обновление: Default Game Profiles, функция, автоматически подбирающая оптимальный баланс между FPS и энергопотреблением. Она будет работать в отдельных играх и поможет значительно продлить автономность устройства.
На этом Microsoft останавливаться не собирается: в начале 2026 года ожидается запуск AI-инструментов, включая Auto SR (Automatic Super Resolution) — систему автоматического апскейлинга на базе ИИ, аналог DLSS. Также появится функция highlight reels для Xbox Ally X, которая, вероятно, будет автоматически сохранять лучшие игровые моменты. Улучшения коснутся и режима док-станции, превратив Ally в полноценную консоль или ПК с подключением к монитору.
Microsoft подчёркивает, что будет регулярно улучшать производительность, время работы и совместимость игр в портативном режиме. Несмотря на постепенное устаревание «железа», новые функции и оптимизации должны сохранить актуальность Xbox Ally в ближайшие годы. Это лишь старт, и разработчики обещают, что потенциал консоли будет раскрываться с каждым апдейтом.
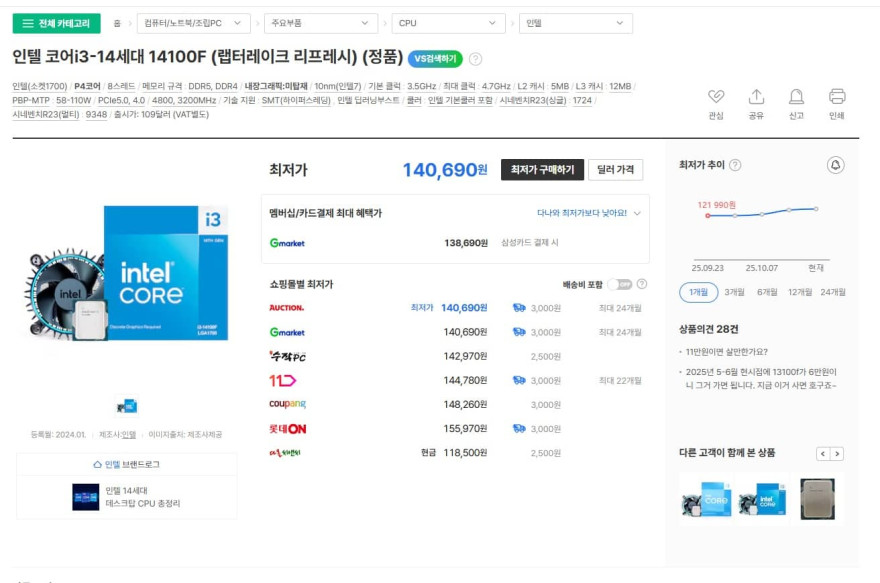
Intel начала повышение цен на популярные процессоры Alder Lake, Raptor Lake и Raptor Lake Refresh, особенно в сегменте Core i3 и Core i5. По данным азиатских ретейлеров, в Южной Корее и Японии зафиксировано рост цен до 20% на ключевые модели среднего сегмента, включая Core i5-14400, i5-12400F и i3-14100F. В отдельных случаях прирост составил от 11% до 15% всего за три недели.
В Корее платформа Danawa отмечает рост стоимости Core i3-14100F на 15%, а Core i5-14600KF и 12400F прибавили 13% и 11% соответственно. Японские данные от GAZ:Log фиксируют +20% на Core i5-14400, а также умеренное повышение в 5% на Core i7-14700K/KF. Цены выросли преимущественно на самые продаваемые SKU, что говорит о целенаправленной стратегии Intel.
Повышение цен затронуло даже 12-е поколение Alder Lake, несмотря на выход новых Core Ultra 200S (Arrow Lake). Причиной может быть слабый интерес к Arrow Lake: высокие цены и акцент на AI не оправдали ожиданий. Учитывая, что Alder и Raptor Lake производятся на собственном техпроцессе Intel 7, компания имеет больше контроля над себестоимостью и может манипулировать ценами без зависимости от подрядчиков вроде TSMC. Таким образом, Intel не снижает цену на новые Arrow Lake, а повышает стоимость проверенных моделей, чтобы компенсировать слабые продажи новинок.
Компания EXO Labs представила EXO 1.0 — открытую платформу для запуска больших языковых моделей (LLM) на разнородной вычислительной технике, включая десктопы, серверы и даже смартфоны. Новый демо-проект продемонстрировал, как две станции NVIDIA DGX Spark могут работать в паре с Apple Mac Studio на чипе M3 Ultra, формируя единое решение для ускоренного вывода моделей. Вместо монолитного подхода EXO реализует дизагрегированный вывод, распределяя различные этапы обработки между системами — предварительный анализ (prefill) поручается GPU-системе, а генерация токенов (decode) — высокоскоростному чипу Apple.
В системе использовалась 10-гигабитная сеть Ethernet для потоковой передачи данных KV-кэша, что позволило одновременно задействовать оба устройства без простоев. Концепция базируется на различии в характере нагрузки: этап prefill требует высокой вычислительной мощности, в чём хорош DGX Spark с 100 TFLOPS (fp16), а decode — зависим от пропускной способности памяти, где M3 Ultra с 819 ГБ/с выигрывает. В тесте на модели Llama 3.1 8B гибридная система достигла почти троекратного ускорения по сравнению с Mac Studio, при этом обеспечив производительность на уровне Spark в prefill и рекордное время генерации на этапе decode.
EXO Labs продвигает идею гибкого масштабирования ИИ без необходимости в дорогостоящем едином ускорителе. Подобную архитектуру уже начинает развивать NVIDIA в рамках платформы Rubin CPX, где разные чипы обрабатывают prefill и decode раздельно. Но EXO делает это уже сейчас — на открытом ПО и потребительском «железе». Пока версия 1.0 доступна только по приглашениям, но это первый шаг к миру, где ИИ может использовать любую технику — эффективно и масштабируемо.
Система на базе Ryzen 5 8500G и материнской платы ASUS B850M-A YW GAMING WIFI показала стабильную работу с памятью DDR5-10600, что соответствует 5300 МГц по фактической частоте. Использовалась пара модулей G.SKILL 2×24 ГБ с профилем EXPO CL26 и напряжением 1.580 В.
На скриншотах MemTestPro показано 200% покрытия на всех 16 потоках без единой ошибки, что полностью подтверждает стабильность работы. Тайминги составили 50-58-58-110-160, контроллер памяти работал на 2650 МГц, CR — 2T. Платформа использовала прошивку с микрокодом AGESA ComboAM5PI 1.1.7.0.
Результат выделяется не только высокой частотой, но и общим объёмом памяти — 48 ГБ, что подчёркивает надёжность AM5 с Phoenix 2 даже при экстремальных настройках. Это один из самых стабильных разгонов DDR5 на бюджетном APU, зафиксированных с полным прохождением теста.