




NVIDIA побила рекорд скорости генерации текста с Llama 4 Maverick — 1038 токенов в секунду
Компания NVIDIA установила новый мировой рекорд скорости обработки токенов на одного пользователя, достигнув 1038 токенов в секунду (TPS/user) в модели Meta Llama 4 Maverick. По данным аналитиков Artificial Analysis, этот результат был зафиксирован на кластере DGX B200, оснащённом восемью GPU архитектуры Blackwell, и превзошёл предыдущего лидера — SambaNova — на 31%.
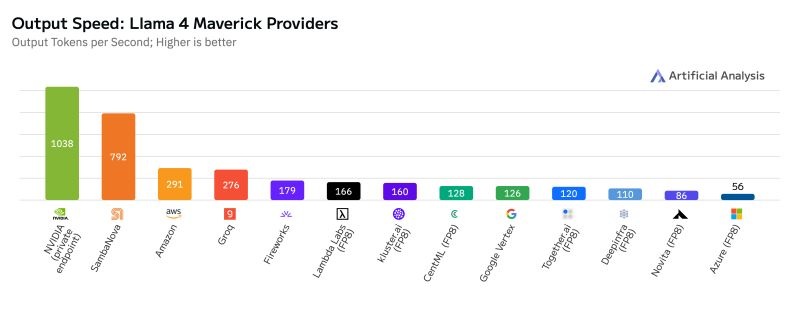
До этого момента рекорд принадлежал компании SambaNova с результатом 792 TPS/user, но NVIDIA значительно опередила всех конкурентов благодаря ряду технических оптимизаций. В частности, для Llama 4 Maverick была задействована библиотека TensorRT и методика спекулятивного декодирования Eagle-3, позволяющая предугадывать выходные токены заранее. Только эти две технологии обеспечили 4-кратный прирост производительности по сравнению с предыдущими результатами Blackwell.
График производительности показывает, что NVIDIA и SambaNova ушли далеко вперёд от остальных участников. Amazon (291 TPS) и Groq (276 TPS) следуют на третьем и четвёртом местах, в то время как остальные компании, включая Google Vertex, Together.ai, Deepinfra, Novita и Azure, не смогли преодолеть планку в 200 TPS. Платформы Fireworks, Lambda Labs и Kluster.ai тоже отстали, продемонстрировав менее 180 TPS/user.
Стоит отметить, что показатель TPS/user (токенов в секунду на одного пользователя) фокусируется именно на производительности при индивидуальной генерации, а не пакетной обработке, что особенно важно для чат-ботов и ИИ-сервисов в реальном времени. Чем выше TPS, тем быстрее ИИ отвечает на пользовательские запросы — ключевой фактор в повседневной работе таких моделей.
Кроме скорости, NVIDIA улучшила точность вывода, используя формат данных FP8 вместо BF16, а также технику Mixture of Experts и оптимизации на уровне CUDA-ядер: пространственное разбиение и динамическое перемешивание весов GEMM. Всё это указывает на то, что NVIDIA укрепляет лидерство в AI-инфраструктуре, особенно в области LLM.