AMD и OpenAI объявили о масштабном партнёрстве, в рамках которого OpenAI развернёт инфраструктуру мощностью до 6 гигаватт на базе Instinct GPU от AMD. Первая волна — 1 ГВт на базе нового ускорителя MI450, запуск которого намечен на вторую половину 2026 года.
Ускорители AMD Instinct MI450 обеспечат до 40 PFLOPs вычислений, будут оснащены 432 ГБ памяти HBM4 и обеспечат пропускную способность до 19,6 ТБ/с. Эти показатели почти вдвое превышают характеристики предыдущего поколения MI300X. Новые чипы станут ядром будущей архитектуры OpenAI, но также будут использоваться и другие модели Instinct — включая серии MI300 и MI350.
Сотрудничество включает многоуровневую договорённость: AMD предоставит OpenAI варранты на до 160 млн акций, которые будут постепенно активироваться по мере масштабирования закупок от 1 до 6 ГВт. Также будут учитываться как рыночные показатели AMD, так и успехи OpenAI в развертывании инфраструктуры.
Руководители обеих компаний подчеркивают важность технологического альянса: “партнёрство ускорит глобальное внедрение ИИ”, а AMD ожидает десятки миллиардов долларов выручки от сделки. Это один из крупнейших контрактов в сфере ИИ-вычислений на сегодняшний день.
Портативная консоль от Microsoft, о которой в последнее время активно ходили слухи, по неподтверждённой информации была отменена из-за высоких требований AMD к объёму заказа. Об этом сообщил инсайдер Kepler_L2, ранее точно раскрывавший данные о консолях и продуктах AMD.
По его словам, AMD была готова разрабатывать отдельный SoC для портативной Xbox, но только при минимальном заказе в 10 миллионов устройств. Однако, учитывая, что Steam Deck продался тиражом около 5 миллионов, а ASUS ROG Ally — менее 2 миллионов, Microsoft не стала брать на себя такие риски.
Хотя консоль никогда официально не анонсировалась, представители Xbox не раз намекали на портативную стратегию, которая теперь, по всей видимости, сосредоточится на ROG Ally с брендингом Xbox. Этот гибрид от ASUS уже демонстрирует высокий спрос — устройство раскуплено ещё до старта продаж 16 октября, несмотря на высокую цену.
По некоторым предположениям, отказ от собственного железа может быть частью новой модели Microsoft, которая всё чаще рассматривается как издатель с мультиплатформенным фокусом, а не производитель строго своих устройств.
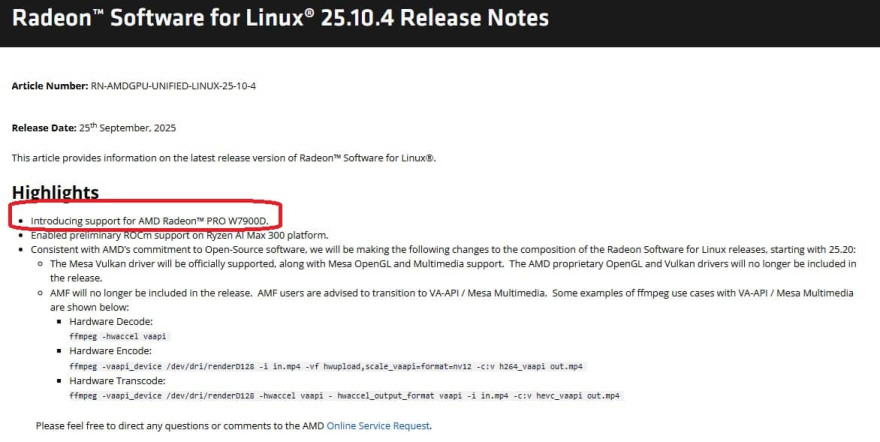
Компания AMD незаметно представила новую модель видеокарты Radeon PRO W7900D, которая была обнаружена в свежем выпуске драйвера Radeon Software for Linux 25.10.4. В примечаниях к релизу от 25 сентября 2025 года указано, что драйвер добавляет поддержку Radeon PRO W7900D, что стало первым официальным упоминанием этого SKU.
До этого момента в серии были представлены две модели — Radeon PRO W7900 и W7900 Dual Slot, обе построены на чипе Navi 31, содержат 6144 потоковых процессора и оснащены 48 ГБ памяти GDDR6. Модель Dual Slot отличалась более компактной системой охлаждения и вышла позже по сниженной цене.
Модель W7900D пока отсутствует на официальном сайте AMD, включая китайскую версию, где, как предполагается, она могла бы быть представлена в первую очередь. Буква "D" в названии наводит на аналогию с серией NVIDIA RTX 4090D/5090D, выпущенной специально для китайского рынка. Хотя слухи о региональных вариантах от AMD ходят давно, официального подтверждения до сих пор не было.
Компания NVIDIA планирует внедрить новую систему охлаждения для будущей линейки Rubin Ultra AI, чтобы справиться с растущими требованиями к энергопотреблению и температурному контролю. Речь идёт о микроканальных холодных пластинах (MCCP), которые позволят достичь оптимального соотношения производительности на ватт.
Технология MCCP работает по принципу прямого охлаждения кристалла, аналогично решениям энтузиастов разгона, использующих direct-die для процессоров. Внутри медной пластины создаются тонкие каналы, по которым циркулирует хладагент, обеспечивая локальную конвекцию и снижение теплового сопротивления между кристаллом и жидкостью. Такой подход эффективнее стандартных водоблоков и особенно актуален для серверных систем с экстремальной нагрузкой.
Ранее предполагалось, что MCCP появятся уже в базовых GPU Rubin (TDP до 2,3 кВт), но трудности с массовым производством затормозили переход. По данным @QQ_Timmy, NVIDIA теперь делает акцент на Rubin Ultra, готовящийся к запуску в 2027 году, и поручила разработку MCCP компании Asia Vital Components (AVC). Интересно, что Microsoft также продвигает микрофлюидное охлаждение, ориентированное на размещение хладагента внутри или позади самого кремния, что делает MCCP логичным промежуточным этапом к будущим технологиям.
С учётом перехода от Blackwell к Rubin, каждая новая архитектура требует всё более изощрённых решений отвода тепла. В таких условиях индустрия жидкостного охлаждения не только не теряет актуальности, но и переходит на совершенно новый технологический уровень.
Компания Qualcomm выпустила новый графический драйвер для Adreno GPU версии 31.0.121.0, ориентированный на повышение стабильности и производительности на устройствах с Snapdragon X Elite. Хотя графика Adreno не считается оптимальной для игр, свежие обновления демонстрируют готовность улучшать ситуацию до выхода следующего поколения — Adreno X2, которое обещает двукратный прирост мощности.
В новом драйвере улучшена стабильность и качество в таких играх, как DIRT 5, Red Dead Redemption 2, Valheim, Horizon Zero Dawn, а также в популярных проектах вроде Fortnite, Dota 2 и Final Fantasy XV. В некоторых тайтлах отмечен прирост производительности, особенно в Alien: Rogue Incursion и Fortnite. Кроме того, драйвер вносит улучшения в AutoCAD и Adobe Camera Raw, повышая стабильность при работе с графикой и чертежами.
Важные обновления коснулись и поддержки дисплеев: добавлена работа с DisplayPort 1.1 HBR2, улучшен механизм резервного считывания EDID-информации, устранены ошибки с пиксельной частотой и выбором режима, что делает отображение более стабильным и надёжным. Также драйвер впервые добавляет OpenCL-расширение cl_khr_external_semaphore_dx_fence, предназначенное для разработчиков, использующих параллельные вычисления.
Этот драйвер не распространяется на будущий Snapdragon X2 Elite, запуск которого ожидается позже. Тем не менее, шаги по улучшению Adreno GPU на текущем поколении могут стать началом новой эры поддержки драйверов на ARM-платформах для Windows.
Ровно 75 лет назад три учёных из Bell Labs — Джон Бардин, Уолтер Браттейн и Уильям Шокли — получили патент на транзистор, что стало началом третьей промышленной революции. Этот скромный на вид элемент с тремя электродами стал основой кремниевой эры, которая до сих пор формирует современный бизнес, технологии и общество.
Первый рабочий прототип был продемонстрирован в 1947 году, но патент на "трёхэлектродный элемент из полупроводников" учёные получили лишь 3 октября 1950 года. Масштаб влияния транзистора осознали не сразу — потребовались годы, чтобы оценить его революционную роль в ускорении вычислений, повышении энергоэффективности и миниатюризации техники. Именно транзисторы позволили создать интегральные схемы и процессоры, где сегодня работают сотни миллиардов элементов на площади меньше ногтя.
До транзисторов использовались вакуумные лампы — хрупкие, громоздкие и прожорливые. Сегодня они остались только в нишевых сферах — гитарных усилителях, студийной акустике и в специализированной военной или научной технике. Основной прогресс ушёл далеко вперёд, и теперь нас ждут чипы с триллионом транзисторов, что когда-то казалось фантастикой.
Одной из вех в истории стал 1965 год — рождение закона Мура, выдвинутого сооснователем Intel Гордоном Муром. Он предсказал, что число транзисторов в чипах будет удваиваться каждые два года, что стало направляющим принципом всей индустрии. Несмотря на сомнения, многие инженеры и компании по-прежнему считают, что закон Мура жив, а его дух — основа нынешней гонки за искусственным интеллектом и новым уровнем машинного мышления.
intendo Switch 2 оказалась единственной крупной консолью с графикой от Nvidia, и именно это позволяет ей использовать технологию DLSS для масштабирования изображения. Теперь выяснилось, что DLSS в Switch 2 существует в двух версиях, каждая из которых адаптирована под разные сценарии работы — подтверждено анализом Digital Foundry.
Первый вариант, «полноценный DLSS», схож с тем, что используется на ПК. Он задействует CNN-модель и ограничен разрешением до 1080p, но при этом выдаёт максимально чёткое и стабильное изображение, минимизирует артефакты и отлично справляется с движением и сменой кадров. Этот режим обеспечивает лучшее качество, но требует больше ресурсов.
Второй — это «DLSS Light», разработанный специально для Switch 2 и позволяющий масштабировать картинку выше 1080p, вплоть до 4K в док-режиме. Однако он делает это с меньшей нагрузкой на систему — в два раза дешевле по времени кадра, но страдает при движении, отключая временные методы реконструкции и создавая заметные искажения. В статике изображение выглядит отлично, но теряет чёткость при любом движении.
Интересно, что пока ни одна игра Nintendo не использует DLSS, а основное применение технологии наблюдается в сторонних тайтлах, таких как Cyberpunk 2077, Hogwarts Legacy, Street Fighter 6 и других. В будущем есть надежда, что новая модель DLSS на базе трансформеров тоже доберётся до Switch 2, что может серьёзно изменить картину в плане производительности и визуального качества.
Флагман Apple iPhone 17 Pro Max стал лидером в новом тесте автономности от PhoneBuff, опередив как Galaxy S25 Ultra, так и Pixel 10 Pro XL. Хотя ранее именно смартфон Samsung одержал победу в спидтесте, теперь расстановка сил изменилась — и Apple взяла реванш.
Общий сценарий включал реальные условия использования: браузинг, Instagram, Snapchat и 16 часов ожидания, при этом тест имитировал интенсивную повседневную нагрузку. Во всех задачах iPhone 17 Pro Max показал лучшую энергоэффективность, особенно в сегменте работы с социальными сетями. При этом все три устройства использовали LTPO OLED-дисплеи с адаптивной частотой до 120 Гц, но именно Apple удалось реализовать эту технологию наиболее эффективно.
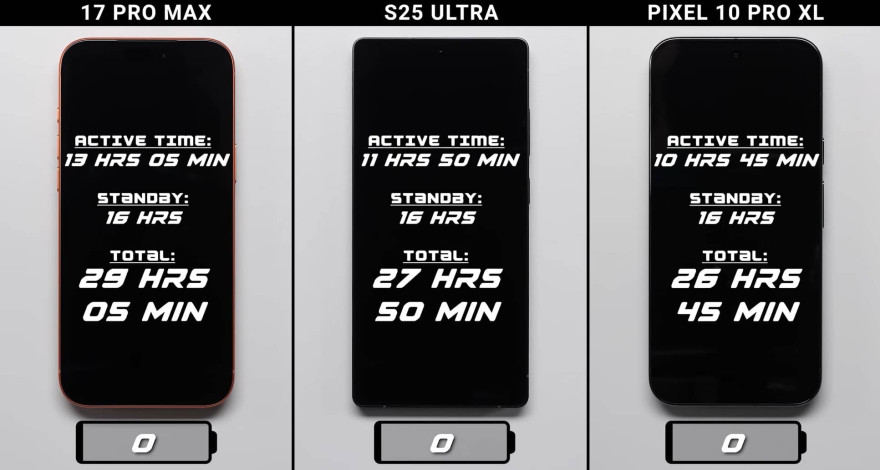
Финальные результаты теста:
iPhone 17 Pro Max: 13 ч 05 мин активной работы + 16 ч ожидания = 29 ч 05 мин
Galaxy S25 Ultra: 11 ч 50 мин активной работы + 16 ч ожидания = 27 ч 50 мин
Pixel 10 Pro XL: 10 ч 45 мин активной работы + 16 ч ожидания = 26 ч 45 мин
Особенно показательно финальное испытание — Snapchat, где активны экран, GPS, Wi-Fi и камера. Здесь Pixel 10 Pro XL сдался первым, несмотря на самый крупный аккумулятор. За ним — Galaxy S25 Ultra. А iPhone 17 Pro Max остался на плаву до самого конца, что и обеспечило ему победу.
PhoneBuff отмечает, что у Apple ещё есть потенциал для оптимизации в iOS 26, а значит, результат может быть улучшен в будущих апдейтах.
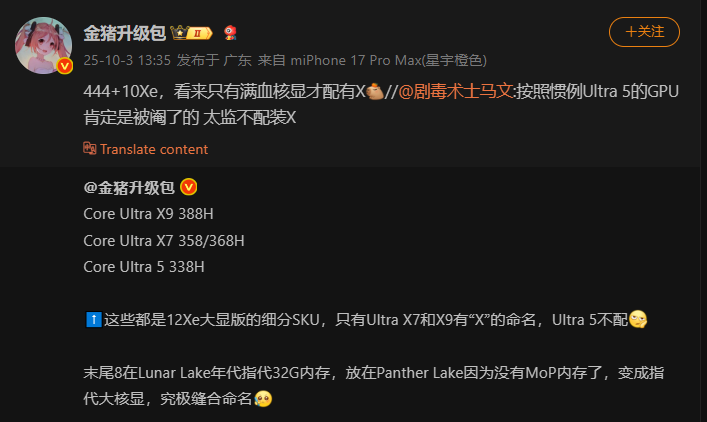
Intel готовит серьёзное обновление встроенной графики в линейке мобильных процессоров Panther Lake, впервые внедряя iGPU Xe3 (Celestial). При этом только версии с маркировкой "X", такие как Core Ultra X9 и X7, сохранят полную конфигурацию из 12 графических ядер Xe3, тогда как обычные модели получат 10 ядер.
Intel планирует использовать новую схему наименования — Core Ultra X7/X9 3X8H, что отражает гибридное происхождение архитектур Arrow Lake-H и Lunar Lake. Название "X" будет обозначать старшую версию iGPU, упрощая потребителю выбор.
На данный момент известно о четырёх X-моделях в серии Panther Lake:
Core Ultra X9 388H (16 CPU-ядер): 12 Xe3-ядер
Core Ultra X7 358H (16 CPU-ядер): 12 Xe3-ядер
Core Ultra X7 368H (16 CPU-ядер): 12 Xe3-ядер
Core Ultra 5 338H (12 CPU-ядер): 10 Xe3-ядер
Таким образом, даже базовые чипы без "X" остаются мощными решениями с продвинутой графикой Xe3, пусть и не в полном объёме. В сравнении с Lunar Lake, Panther Lake предлагает больше CPU-ядер (до 16 в серии H и от 6 до 8 в U), а также гибкую конфигурацию памяти без ограничения встроенной LPDDR5X, что характерно для прошлых моделей.
Переход к новой архитектуре также позволит добиться высокой автономности, унаследованной от Lunar Lake, при этом предлагая более универсальный набор функций и производительности в сегменте ноутбуков.
На фоне продолжающихся проблем с процессорами AMD Ryzen 9000 блогер с YouTube-канала Tech YES City опубликовал новое видео, в котором попытался разобраться в причинах массового выхода чипов из строя, особенно при использовании с материнскими платами ASRock серии X870. В ходе анализа он выдвинул теорию о возможном заводском браке отдельных партий процессоров.
Особое внимание блогера привлекли процессоры с OPN-кодом CF2449PGE. Именно эта партия фигурирует в 28 подтверждённых случаях поломки, включая модели Ryzen 9800X3D. В то же время существуют и другие партии, которые ни разу не упоминались в отчётах о сбоях, что, по мнению автора, указывает на возможную избирательность проблемы.
Также отмечается, что большинство неисправностей возникает в течение первых трёх месяцев эксплуатации, что может указывать на скрытый дефект, проявляющийся в начальной фазе жизненного цикла. При этом некоторые пользователи, столкнувшиеся с поломками, сообщают, что после замены чипа на другую модель — например, с Ryzen 9800X3D на Ryzen 7950X — система продолжает работать стабильно на той же плате более 9 месяцев.
Блогер приводит и собственный случай, когда его Ryzen 9950X сгорел на плате ASRock X870 Steel Legend, но заменённый по гарантии аналогичный чип работает исправно, несмотря на установку в ту же материнскую плату. Кроме того, внешние различия между сгоревшим и новым экземплярами позволяют предположить, что AMD внесла изменения в конструкцию процессоров без публичных объявлений.