Первым крупным шагом Лип-Бу Тана на посту генерального директора Intel стали массовые увольнения, которые теперь получили официальное подтверждение. Согласно отчёту компании, за три месяца под его руководством Intel сократила 20 500 рабочих мест, а с учётом предыдущего этапа реструктуризации общее число уволенных за два года достигло 35 500 человек.
По состоянию на сентябрь 2025 года в корпорации трудятся 88 400 сотрудников, включая 83 300 непосредственно в Intel и 5100 в дочерних структурах, таких как Mobileye. Для сравнения: в конце 2024 года численность персонала составляла почти 109 000 человек. Основная волна увольнений пришлась на второй квартал, что подтверждают реструктуризационные расходы свыше 1 млрд долларов, против 175 млн в следующем квартале.
Несмотря на заявление о «сокращении менеджерского слоя», большая часть увольнений пришлась на инженеров и технический персонал в Орегоне — лишь 8 % сокращённых имели управленческие должности. Параллельно компания урезала R&D-бюджет более чем на 800 млн долларов, несмотря на рост выручки, что указывает на закрытие ряда исследовательских программ.
Финансовый директор Дэвид Зинснер подтвердил, что в 2026 году операционные расходы останутся на уровне $16 млрд, а инвестиции будут направляться только в проекты с «чёткой отдачей» — в частности, в техпроцессы 18A и 14A, AI-ориентированные продукты и передовые методы упаковки чипов. Сам Лип-Бу Тан заявил, что новая стратегия делает Intel «меньше, но сильнее», с приоритетом на клиентский, дата-центрический и фабричный бизнесы, а ключевая цель — долгосрочная прибыльность при строгом контроле затрат.
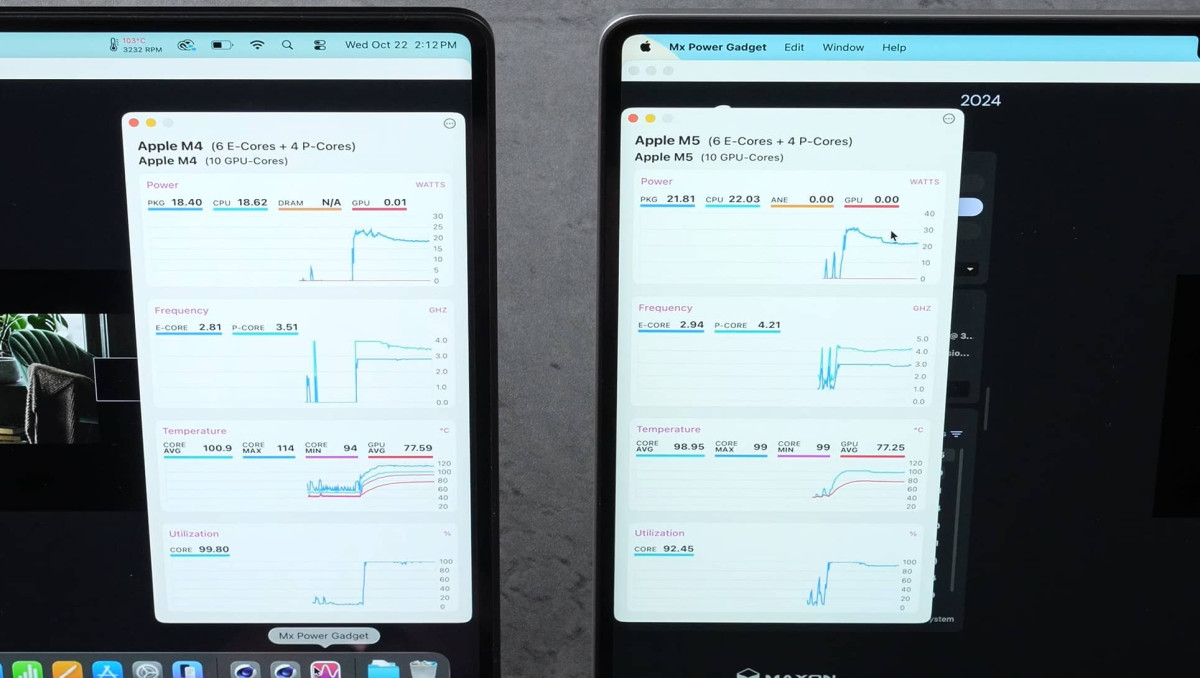
Новая серия M5 MacBook Pro демонстрирует лучшее тепловое поведение по сравнению с предшественником, хотя система охлаждения осталась прежней. Тесты показали, что при полной нагрузке в Cinebench 2024 температура M5 достигает 99 °C, тогда как M4 легко превышает 100 °C, фиксируя максимум 114 °C.
Оба ноутбука оснащены одним вентилятором и одной тепловой трубкой, что для мощных чипов уже на грани допустимого. Тем не менее, M5 удерживает температуру ниже критической отметки, несмотря на более высокое энергопотребление — 21,8 Вт против 18,4 Вт у M4. Это указывает на то, что Apple либо изменила алгоритм работы вентилятора, либо применяет новый термоинтерфейс, вероятно PTM7950, который способен конкурировать с жидким металлом.
Согласно тестам Max Tech, при одинаковом шасси и охлаждении M5 работает стабильнее, демонстрируя заметный прирост FPS даже в Cyberpunk 2077 с включённым трассированием света, что говорит об улучшенном тепловом балансе и распределении нагрузки между CPU и GPU. Несмотря на температурные пики, чип не уходит в троттлинг, что делает M5 одной из самых эффективных реализаций архитектуры Apple Silicon в ноутбуках.
Хотя Radeon AI PRO R9700 официально представили ещё летом, на прилавках карта появится только 27 октября. Партнёры AMD, включая PowerColor, отложили старт продаж, так как ориентированы в первую очередь на OEM-сборщиков. Теперь компания представила третий вариант дизайна, и он стал ещё проще и строже.
Новая версия, под обозначением AI PRO R9700 32G-B, получила меньше логотипов PowerColor и полностью минималистичный корпус. В комплект входит адаптер 12V-2×8 (102 pin) с жёлтым наконечником — тот же тип, что массово использовался в продуктах MSI и часто упоминался из-за случаев перегрева.
Карта сохраняет референсный дизайн с турбинным охлаждением, чип Navi 48 (4096 потоковых процессоров) и 32 ГБ GDDR6 через 256-битную шину. Есть поддержка PCIe 5.0 ×16 и четырёх DisplayPort 2.1a. При стартовой цене $1299 — это самое доступное решение с 32 ГБ видеопамяти в сегменте AI-рабочих станций.
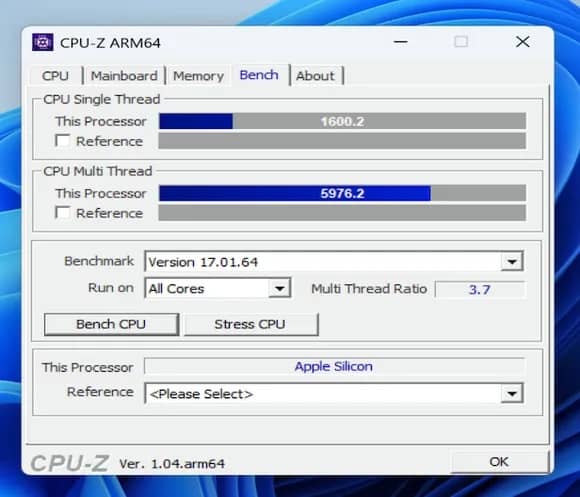
Новый Apple M5 вновь подтвердил репутацию абсолютного лидера по эффективности ядер — даже вне экосистемы macOS. Китайский энтузиаст NPacific протестировал процессор под Windows 11 в режиме виртуализации, и результат оказался ошеломляющим: 1600,2 балла в однопоточном тесте CPU-Z 1.04.arm64. Это абсолютный рекорд среди всех неразогнанных CPU, включая флагманы Intel Core i9-14900KS (952 балла) и AMD Ryzen 9 9950X3D (867 баллов).
Архитектура Armv9 с частотой до 4,6 ГГц позволила M5 превзойти Raptor Cove на 68% и Zen 5 — на 84,5%, что демонстрирует невероятный запас по производительности на такт. Даже учитывая, что тест проходил в виртуальной среде, M5 показал недостижимые результаты для десктопных чипов, работающих при куда более высоких частотах. Apple, как и прежде, делает ставку на максимальную эффективность одного ядра — стратегию, которая приносит всё более впечатляющие итоги.
В многопоточном тесте CPU-Z M5 с 10 ядрами без SMT набрал 5976,2 балла, что сопоставимо с Core i7-12700K (5533) и Ryzen 9 7900X (5935). Однако он остаётся позади современных 12–16-ядерных решений вроде Ryzen 9 9950X3D, что объясняется ограниченным числом потоков и особенностями работы Windows 11 с архитектурой Apple Silicon. При этом стоит отметить, что тест запускался не на macOS, а в эмуляции, что неизбежно ограничивает производительность.
Даже с этим ограничением M5 демонстрирует феноменальную однопоточную мощность, показывая, насколько далеко Apple ушла в проектировании кастомных ядер. Если в будущих тестах появятся результаты из Geekbench или SPECint, можно ожидать ещё более впечатляющих цифр.
После серии громких решений — повышения цен на Game Pass и сокращений в студиях — Microsoft решила развеять сомнения поклонников. Глава Xbox Фил Спенсер в интервью Famitsu подтвердил, что компания готовит новое поколение консоли и не собирается покидать рынок игрового «железа». По словам топ-менеджера, следующий Xbox станет полноценным продуктом Microsoft, и хотя сроки релиза пока не определены, вероятный запуск ожидается в 2027–2028 годах, если компания сохранит семилетний цикл.
Интересная деталь — намёк на возможную гибридную архитектуру. Спенсер отметил, что устройство ROG Xbox Ally, созданное вместе с ASUS, показывает направление развития платформы: объединение всех устройств в единую экосистему Xbox и Windows. Это может означать, что будущая консоль станет гибридом между ПК и консолью, способным запускать Xbox-игры нативно на Windows с общей библиотекой и сохранениями. Идея идеально ложится в стратегию «Play Anywhere», где игрок не ограничен конкретным устройством.
На фоне этих заявлений стоит и другая тенденция — рост давления на прибыльность. Финансовый директор Microsoft Эми Хуад установила для Xbox планку в 30% маржи, что в полтора-два раза выше отраслевых стандартов. Это уже привело к росту цен на Game Pass, закрытию студий и мультиплатформенным релизам, которые приносят быструю выручку за счёт публикации на PlayStation. Внутри Microsoft явно идут структурные перестройки, где каждый новый шаг в консольной стратегии должен быть финансово оправдан.
Тем не менее, руководство Xbox сохраняет уверенность. Президент подразделения Сара Бонд ранее описала будущую консоль как «премиальный, высококлассный и тщательно продуманный опыт». Если компания сумеет совместить производительность, портативность и цену ниже $1000, то новый Xbox сможет стать альтернативой апгрейду игрового ПК. Но если экономическая логика перевесит инновации, риски для бренда возрастают: рынок уже воспринимает Xbox как сервис, а не устройство.
Компания Retro Games Ltd готовит к выпуску The A1200 — полноразмерную современную версию знаменитого Amiga 1200, сочетающую оригинальный дизайн и современные технологии. Предзаказы стартуют 10 ноября, а первые поставки начнутся в июне 2026 года. Цена пока не раскрыта, но уже известно: устройство нацелено стать самой ностальгической машиной для фанатов ретро-компьютеров.
В основе The A1200 — одноплатный Linux-компьютер с эмуляцией Amiga, вероятно, на базе UAE. Главное отличие от самодельных решений вроде Raspberry Pi — полноразмерный корпус с рабочей клавиатурой, точно повторяющий оригинал 1992 года. Вместе с устройством поставляются легендарная “танковая” мышь и геймпад в стиле CD32, а внутри предустановлено 25 классических игр, включая Turrican, Beneath a Steel Sky и The Settlers 2, недавно портированную на Amiga.
Каждая игра получила четыре слота сохранений, что делает возможным комфортное прохождение даже тех проектов, где сейвы изначально отсутствовали. Помимо игр, система предлагает интегрированный рабочий стол Workbench, ту самую среду, которая в 80-е поразила пользователей многозадачностью. Пока не уточнено, какая версия Workbench будет установлена, но, вероятно, 3.0 или 3.1 — для аутентичности эпохи.
The A1200 продолжает традицию Retro Games Ltd по возрождению классики: ранее компания выпустила мини-версии Commodore 64, VIC 20, ZX Spectrum и Amiga 500. Новый проект идёт дальше — это не просто мини-консоль, а полноценный ретро-компьютер, готовый к работе из коробки. С подключением через USB, поддержкой ADF и HDF, а также фирменной клавиатурой, The A1200 превращается в настоящее «окно в 90-е» — без необходимости разбираться с эмуляторами и сборками.
AMD официально подтвердила: Radeon AI Pro R9700, самая мощная графическая карта на архитектуре RDNA 4, поступит в продажу 27 октября по цене $1299. Модель позиционируется как рабочее решение для локальных AI-нагрузок, способное запускать крупные модели прямо на рабочей станции без обращения к дата-центру.
Новинка построена на чипе Navi 48, том же, что используется в Radeon RX 9070 XT, и включает 4096 потоковых процессоров, 128 ROPs и аналогичное количество ядер трассировки. Главное отличие — удвоенный объём видеопамяти: 32 ГБ GDDR6 с 256-битной шиной, что делает R9700 самой доступной 32-гигабайтной рабочей видеокартой на рынке.
По данным AMD, Radeon AI Pro R9700 обеспечивает вдвое более высокую производительность, чем W7800, в задачах вроде DeepSeek R1 и Flux.1 Schnell. На графике использования VRAM видно, что модели DeepSeek R1 Distill Qwen 32B Q6 и Mistral Small 3.1 24B требуют 27–28 ГБ памяти, тогда как Flux.1 Schnell — около 24 ГБ, что подчёркивает оптимальность 32 ГБ буфера для продвинутых AI-сценариев.
Карты Radeon AI Pro R9700 будут поставляться только через партнёров AMD, включая ASRock и XFX, а некоторые из них — исключительно в составе рабочих станций. Благодаря поддержке AMD ROCm и масштабируемости Multi-GPU, R9700 предназначена для профессиональных систем, где важна высокая пропускная способность и стабильность.
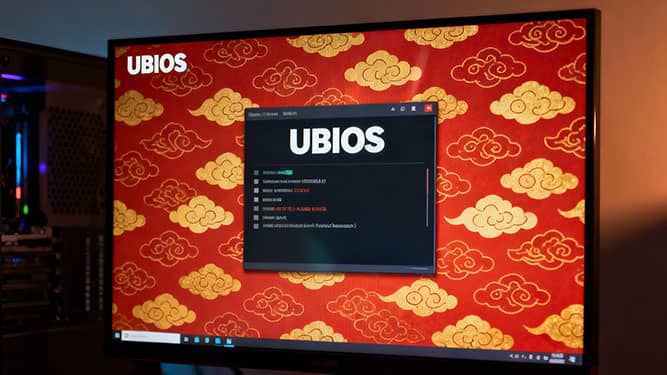
Глобальный вычислительный альянс (GCC) официально представил новый стандарт «Unified Basic Input Output System (UBIOS)» — первую полностью национальную и масштабируемую архитектуру системной прошивки, созданную для замены UEFI. Документ под номером T/GCC 3007—2025 закрепляет основу отечественного стандарта BIOS, ориентированного на распределённую архитектуру и совместную работу аппаратуры и программного обеспечения.
Разработкой стандарта занимались 13 ведущих компаний и исследовательских центров, включая Китайский институт стандартизации электроники, Huawei Technologies, Nanjing B&A Software и Kunlun Taike (Beijing). В отличие от UEFI, UBIOS не является её модификацией или адаптацией, а представляет собой полностью переосмысленную систему низкоуровневого взаимодействия, разработанную с нуля. Среди её ключевых свойств — гетерогенная совместимость, модульная структура, низкая связность, абстрактность и высокая расширяемость.
На протяжении двух десятилетий стандарт UEFI оставался доминирующим решением для BIOS во всех основных системах — от x86 до ARM и RISC-V. Однако со временем его архитектурные ограничения стали серьёзным препятствием для адаптации к современным технологиям, включая гетерогенные вычисления и Chiplet-дизайн. UEFI по-прежнему глубоко связан с экосистемой Intel и Microsoft, что делает его зависимым от западной инфраструктуры.
Создание UBIOS позволяет Китаю впервые сформировать собственную экосистему базового системного ПО, независимую от иностранных спецификаций и кода. Это событие стало стратегическим шагом в укреплении технологического суверенитета, открывая путь к полностью автономной прошивке для ARM, RISC-V и LoongArch.
Компания Microsoft официально представила Mico — новый анимированный аватар для Copilot, который реагирует на голос пользователя, меняет форму и выражает эмоции во время общения. Персонаж представляет собой абстрактное парящее существо, которое «оживает» при взаимодействии, делая голосовые диалоги с искусственным интеллектом более естественными и человечными. Название Mico выбрано как сокращение от Microsoft Copilot.
Mico — необязательная функция, которую можно включить или отключить. Аватар «слушает, реагирует и меняет цвета», визуально показывая участие в беседе. Microsoft уверена, что это поможет людям чувствовать себя комфортнее при голосовом взаимодействии с ИИ. В компании добавили и пасхалку: если нажать на Mico несколько раз, он превращается в легендарного Clippy — бумажного помощника из старых версий Office.
Наряду с Mico, Copilot получил ряд ключевых нововведений. Появилась функция Copilot Groups — групповые чаты до 32 участников, где ИИ способен суммировать обсуждения, предлагать варианты решений, вести подсчёт голосов и распределять задачи. Ещё одно дополнение — режим Real Talk, позволяющий Copilot оспаривать некорректные суждения пользователей, особенно в чувствительных темах. Также представлена функция Copilot Health, основанная на проверенных источниках вроде Harvard Health, помогающая искать медицинскую информацию и специалистов. Все эти возможности входят в осеннее обновление Copilot 2025.
Компания Razer выпустила новый премиальный геймпад Raiju V3 Pro, ориентированный на пользователей PlayStation 5 и ПК. Модель стала зеркальной альтернативой контроллеру Wolverine V3 Pro, предлагая симметричную компоновку стиков и ту же премиальную эргономику.
Контроллер поддерживает частоту опроса 2000 Гц, что вдвое выше, чем у стандартного Wolverine V3 Pro, и обеспечивает почти мгновенный отклик без лишней нагрузки на батарею. В основе конструкции — TMR-стики, устойчивые к дрейфу, а также фирменные HyperTriggers, позволяющие переключаться между коротким кликом и плавным ходом. Добавлены сменные насадки стиков, съёмные задние кнопки и удобные верхние бамперы, ориентированные на киберспортивное использование.
Raiju V3 Pro стоит $220 / £200 и ощущается столь же качественно, как флагманские модели Razer для ПК. По сути, компания впервые перенесла свой топовый дизайн в PlayStation-формат, открыв путь для игроков, предпочитающих симметричную раскладку.