Intel и AMD находятся на ранней стадии переговоров о потенциальном партнёрстве, в рамках которого AMD может стать клиентом Intel Foundry — контрактного производства чипов. По информации из отчёта Semafor, объёмы возможного производства не уточняются, но само обсуждение знаменует важный сдвиг в отношениях двух технологических гигантов.
Сейчас AMD производит свои чипы на мощностях TSMC, а Intel, в свою очередь, также частично полагается на тайваньскую компанию. В последние недели Intel активно укрепляет свои позиции: США приобрели 9,9% акций компании, Softbank инвестировал ещё $2 млрд, а Nvidia — $5 млрд. Кроме того, Intel объявила о совместных x86-чипах с Nvidia и о переговорах с Apple по будущим проектам.
Переговоры с AMD могут стать важной вехой в реализации стратегии бывшего CEO Intel, Пэта Гелсингера, который ставил цель — производить чипы для всех крупнейших компаний, включая конкурентов. Действующий CEO, Лип-Бу Тан, ранее заявлял, что Intel может отказаться от техпроцесса 18A, если спрос на него не оправдает ожиданий. Привлечение AMD стало бы важным шагом к загрузке производственных мощностей.
На фоне геополитики и политики Белого дома, нацеленной на увеличение доли производства чипов внутри США до 50%, такое сотрудничество может быть выгодно обеим сторонам. Для AMD — это возможность получить резервного производителя на случай сбоев у TSMC, особенно с учётом недавних экспортных ограничений со стороны США, затронувших графические решения компании.
Компания ASRock выпустила обновление BIOS версии 3.50 для множества материнских плат на чипсетах X870, B850, B650, B840, A620, Z890 и B860, включающее новую версию микрокода AMD AGESA ComboAM5 1.2.0.3g. Все прошивки стали доступны 26 и 30 сентября 2025 года. Обновление нацелено на оптимизацию производительности и стабильности систем с процессорами AMD Ryzen и Intel Core.
Для платформы AM5, охвачены почти все модели на новых чипсетах X870, B850 и B650. Среди них — X870E Taichi, B850M Pro RS WiFi, B650 Steel Legend WiFi, а также платы на A620, включая A620AM Pro RS и A620M-HDV/M.2+. Все они получили универсальную версию BIOS 3.50 с актуальным AGESA. Это особенно важно на фоне ожидаемой поддержки новых процессоров Ryzen и доработок EXPO-профилей.
Линейка Intel LGA1700 также получила новые прошивки. Модели Z890 Taichi AQUA, Z890 Pro RS WiFi, а также платы на B860, включая B860 Steel Legend WiFi и B860 Pro RS, обновлены до версий 3.11, 2.07 или 1.22 соответственно. Обновления направлены на улучшение совместимости, в том числе с новыми модулями памяти DDR5.
Полный список включает десятки моделей. Все прошивки доступны для загрузки на официальной странице поддержки ASRock. Однако модераторы напоминают, что BIOS может не отображаться сразу — в таком случае следует использовать сочетание CTRL + Shift + R для принудительного обновления кэша страницы. В случае проблем рекомендуется использовать BIOS Flashback, как отметил один из пользователей, столкнувшийся с неполадками при активации EXPO на 6000 МГц.
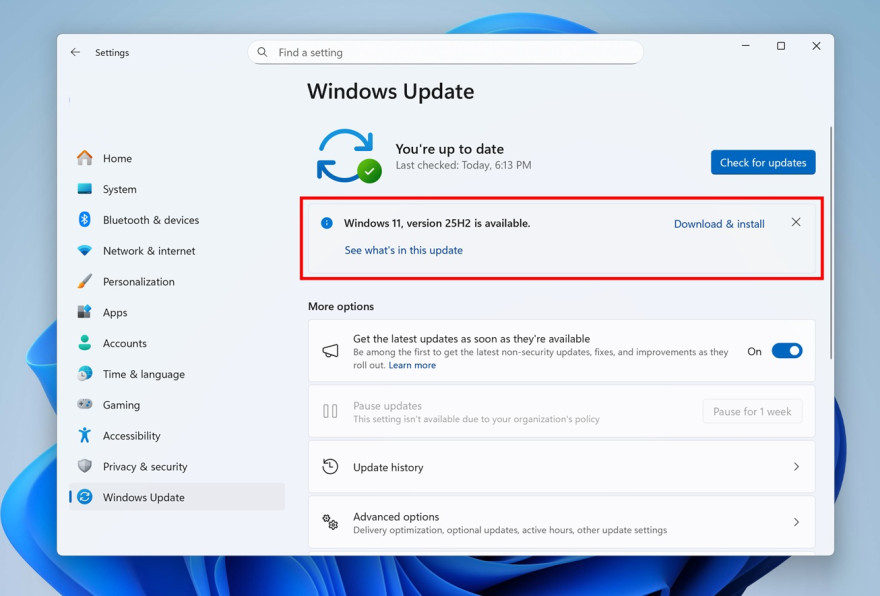
Обновление Windows 11 версии 25H2 стало доступно для широкой аудитории, однако уже в первые часы Microsoft зафиксировала четыре известных проблемы, многие из которых перекочевали из предыдущей сборки 24H2. Поскольку 25H2 является enablement-пакетом, использующим ту же платформу, что и 24H2, она унаследовала ряд багов без необходимости в дополнительных патчах.
Одна из самых серьёзных проблем — неработоспособность DRM-контента. Microsoft сообщает, что в 25H2 нарушена работа Enhanced Video Renderer, компонента, отвечающего за воспроизведение защищённого видео. Это может привести к ошибкам авторских прав, чёрному экрану или полной невозможности воспроизведения фильмов и сериалов в устаревших приложениях, использующих DVD или Blu-ray. Исправление ожидается в октябре 2025 года.
Вторая проблема касается Windows Update Standalone Installer (WUSA). Установка обновлений вручную через .msu-пакеты вызывает ошибку ERROR_BAD_PATHNAME, что особенно критично для корпоративных пользователей. Microsoft признала проблему, но пока не указала сроки её устранения.
Также затронут протокол SMBv1, используемый для сетевого обмена файлами. После обновления до 25H2 невозможно использовать SMBv1 через NetBIOS (NetBT), что влияет на совместимость с устаревшим оборудованием. Microsoft рекомендует перейти на TCP-порт 445, позволяющий использовать SMBv1 без NetBT. Однако корпорация напоминает, что поддержка SMBv1 прекращена, и настоятельно советует перейти на SMBv2 или SMBv3.
Наконец, Media Creation Tool не запускается на ARM64-устройствах, если попытаться создать установочный носитель для ARM64-систем. Пользователи ARM могут лишь создать ISO для x64, но не для собственной архитектуры. Microsoft уже работает над исправлением этой некорректной блокировки.
В сеть утекли первые подробности о мобильных процессорах Intel Panther Lake-H, которые выйдут под новой схемой наименования — Core Ultra X5, X7 и X9. Эти модели станут частью семейства Core Ultra 300 и будут базироваться на 18A техпроцессе с архитектурными улучшениями, включая новые P- и E-ядра, а также iGPU Xe3.
Флагманом линейки станет Core Ultra X9 388H, ориентированный на максимальную производительность с частотой до 5.1 ГГц и высокой плотностью E-ядер. Модель рассчитана на геймерские и рабочие ноутбуки высокого класса, требующие высокой однопоточной производительности и эффективной многозадачности. Следом идёт Core Ultra X7 368H — чип с акцентом на высокую iGPU-производительность и сбалансированную частоту P-ядер — до 5.0 ГГц. Он подойдёт для ноутбуков без дискретной графики.
Также ожидается появление моделей Core Ultra X7 358H и X5 338H, ориентированных на массовый рынок. Первый предлагает немного сниженные характеристики ради тепловой эффективности, а второй станет решением для повседневной производительности с умеренными частотами и сбалансированной архитектурой. Все чипы относятся к H-серии и, судя по классификации, будут применяться в игровых, мультимедийных и производительных ноутбуках.
Спекулятивная таблица утечек даёт представление о предполагаемой структуре линейки. В частности, X7 368H будет оснащён мощной графикой с частотой до 2.5 ГГц, а остальные модели пока остаются без подтверждённых спецификаций. При этом, несмотря на путаницу в утечках, речь идёт именно о Panther Lake-H, а не о Nova Lake, как утверждают некоторые источники.
Компания NVIDIA выпустила драйвер GeForce Hotfix 581.47, основанный на Game Ready версии 581.42, специально для устранения одной конкретной, но критичной ошибки. Новый патч устраняет сбои в играх, которые возникали при включённой функции Smooth Motion, если путь к установленной игре содержал китайские символы. Эта проблема затрагивала ряд пользователей по всему миру и вызывала нестабильность даже на современных системах.
Hotfix-драйверы NVIDIA создаются вне расписания и проходят сокращённый цикл тестирования, позволяя быстрее устранить баги, выявленные в актуальных версиях. В большинстве случаев они включают минимальные изменения по сравнению с предыдущим релизом, но нацелены на точечную оптимизацию стабильности. Все исправления из хотфиксов в дальнейшем включаются в официальные WHQL-сертифицированные драйверы.
Версия 581.47 актуальна для Windows 10 x64 и Windows 11 x64, доступна только через раздел поддержки NVIDIA. Компания подчёркивает, что этот выпуск является бета-версией, предоставляется «как есть», и ориентирован на пользователей, которые готовы оперативно применять исправления без ожидания финальных релизов.
amsung и SK hynix подписали предварительные соглашения о поставке памяти для глобальной инициативы Stargate, которую реализуют OpenAI, Oracle и SoftBank. Вместо готовых чипов, партнёры будут отгружать необрезанные кремниевые пластины DRAM, включая решения на базе DDR5 и HBM, что подчеркивает масштаб проекта. По оценкам, Stargate может поглощать до 40% мирового выпуска DRAM, что эквивалентно 900 тысячам пластин в месяц.
На 2025 год глобальная мощность фабрик составляет около 10 миллионов пластин (300 мм) в месяц, при этом DRAM занимает порядка 22% — около 2,25 миллиона WSPM. OpenAI фактически требует почти половину этого объёма, что создаёт высочайший спрос на память и инфраструктуру для ИИ-вычислений. При этом пока неизвестно, какая из компаний займётся нарезкой пластин и производством конечных модулей памяти.
Stargate предполагает строительство гигантских дата-центров, каждый из которых будет содержать миллионы ИИ-чипов, включая NVIDIA Blackwell, системы охлаждения, электропитания и возможно даже отдельные электростанции. На фоне этого, подразделения Samsung подписали дополнительные соглашения: Samsung SDS займётся архитектурой дата-центров и будет интегрировать решения OpenAI в корпоративные ИТ-системы, а также станет реселлером ChatGPT Enterprise в Южной Корее. Компании Samsung C&T и Samsung Heavy Industries параллельно разрабатывают плавучие дата-центры, чтобы снизить выбросы и повысить эффективность охлаждения.
Технология масштабирования FSR 4 от AMD, изначально рассчитанная на RDNA 3, теперь показывает отличную совместимость с видеокартами Radeon RX 6000 на архитектуре RDNA 2. Сообщения от пользователей, в частности от участника сообщества mario_mendel34, подтверждают, что FSR 4 работает стабильно, если использовать старый драйвер или модифицированный новый. Это позволяет запускать версию FSR-4-INT8-DLL без графических артефактов.
Проверенный метод включает использование драйвера AMD Adrenalin 23.9.1 либо перенос двух DLL-файлов (amdxc32.dll и amdxc64.dll) из этого драйвера в свежую сборку. Замена выполняется вручную с помощью архиватора (например, 7-Zip) путём распаковки обеих версий драйверов и подмены файлов в нужной директории перед установкой. Такая схема позволяет сохранить преимущества нового драйвера, одновременно обеспечивая совместимость с FSR 4.
Визуально качество изображения на RX 6800 оказалось сопоставимым с RX 9070, что подтверждается видеозаписями с разными режимами (Native, Quality, Performance). Автор подчёркивает, что INT8-вариант FSR 4 на RDNA 2 ощущается полноценным, а не упрощённым. Кроме того, первые тесты на Steam Deck, основанном на той же архитектуре, также показали отличную стабильность и прирост качества без значительной потери производительности — особенно при учёте CPU-лимита устройства.
Компания ASRock запустила ограниченную по времени акцию, в рамках которой владельцы материнских плат 800-й серии могут получить дополнительный год гарантии. Стандартная гарантия составляет 2 года, однако при выполнении условий программа предоставляет общий срок гарантии в 3 года (2+1).
Акция распространяется на модели серий Intel Z890, B860, а также AMD X870 и B850. Важно отметить, что серия B840 в кампанию не входит. Условия просты: необходимо зарегистрировать плату в период с 29 сентября по 31 декабря 2025 года через раздел Product Registration на сайте ASRock Fan Club. Дата покупки при этом не имеет значения — главное, чтобы устройство было без дефектов на момент регистрации.
Однако участвовать могут только жители Японии, которые приобрели плату через официальных дистрибьюторов внутри страны. Без этого расширенная гарантия не активируется. Условия акции и интерфейс регистрации подробно описаны на японском сайте компании.
Таким образом, ASRock стимулирует локальных пользователей участвовать в фан-клубе, одновременно повышая лояльность к бренду и снижая риски при долгосрочной эксплуатации плат серии 800.
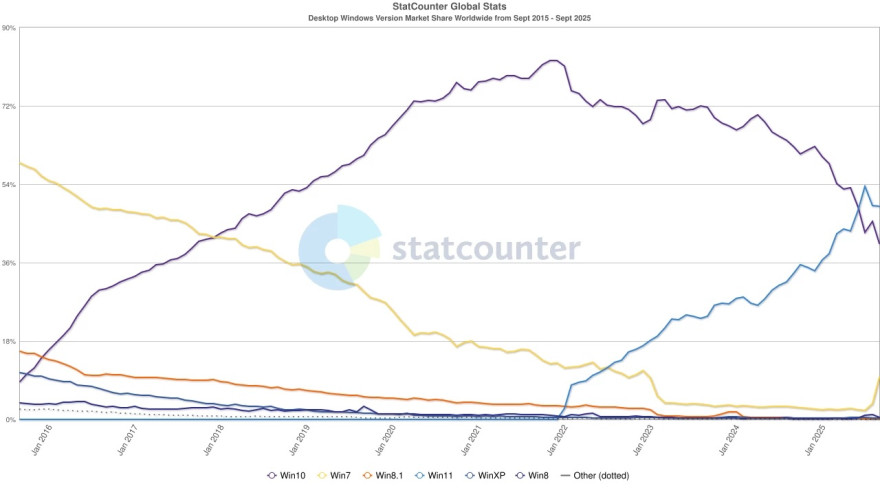
Сервис Statcounter опубликовал свежую статистику использования версий Windows за сентябрь 2025 года. Доля Windows 10 на рынке снизилась до 40,5%, что стало самым низким показателем за последние семь лет. Это падение происходит за две недели до окончания официальной поддержки операционной системы, запланированной на 14 октября 2025 года.
Одновременно с этим наблюдается резкий скачок популярности Windows 7, доля которой увеличилась до 9,61% — уровня, на котором система находилась до завершения программы расширенных обновлений безопасности в январе 2023 года. Причины этого всплеска пока остаются неясными: сложно предположить, что массовый переход на устаревшую ОС может быть случайным или рациональным решением пользователей.
На этом фоне Windows 11 продолжает укреплять позиции и достигла 49,05% рынка, немного снизившись по сравнению с августом. Система остаётся самым популярным выбором среди пользователей, особенно на новых устройствах.
Microsoft напомнила, что пользователи Windows 10 смогут воспользоваться бесплатной регистрацией в программе расширенных обновлений безопасности (ESU), которая предоставит ещё 12 месяцев защитных патчей. Корпоративным клиентам доступны платные обновления вплоть до 2028 года.
Компания Kingston Technology, крупнейший независимый поставщик оперативной памяти, представила новую маркировку «WP» для модулей DDR4, собранных исключительно на чипах собственного производства. Это решение стало ответом на дефицит DDR4-памяти от сторонних производителей, которые всё чаще перераспределяют мощности на выпуск новых типов памяти.
Kingston самостоятельно закупает кремниевые вейферы, проводит нарезку, корпусировку и тестирование кристаллов, сортируя их по электрическим и скоростным параметрам. Такие чипы получают фирменную маркировку и используются при сборке памяти наравне с партнёрскими решениями. В новых модулях с индексом WP (Wafer Processing) используются только внутренние чипы, без участия сторонних производителей.
Несмотря на разницу в происхождении компонентов, все модули остаются полностью совместимыми, и характеристики — как тактовые частоты и тайминги — не отличаются от стандартных. Новая маркировка введена для облегчения логистики, учёта и управления доступностью продукции.
На первом этапе индекс WP применяется к модулям памяти DDR4-3200, в том числе стандартной линейки JEDEC ValueRAM и игровой серии Kingston FURY Beast. Полный список артикулов, получивших маркировку WP:
KF432C16BB/8WP
KF432C16BBK2/16WP
KF432C16BB1/16WP
KF432C16BB1K2/32WP
KF432C16BB2A/8WP
KF432C16BB2AK2/16WP
KF432C16BB12A/16WP
KF432C16BB12AK2/32WP
KVR32N22S8/8WP
KVR32N22D8/16WP
KVR32S22S8/8WP
KVR32S22D8/16WP
Эти модули уже доступны на рынке и служат полноценной заменой существующим версиям, гарантируя высокое качество и стабильность.