На конференции Hot Chips 2025 компания NVIDIA представила обновлённый подход к созданию игр, делая искусственный интеллект ключевой частью графического рендеринга. Архитектура Blackwell перестаёт полагаться исключительно на традиционные методы обработки кадров, заменяя часть вычислений нейросетевыми алгоритмами. Теперь ИИ используется не как дополнительный инструмент, а как встроенный элемент игрового процесса и визуализации.
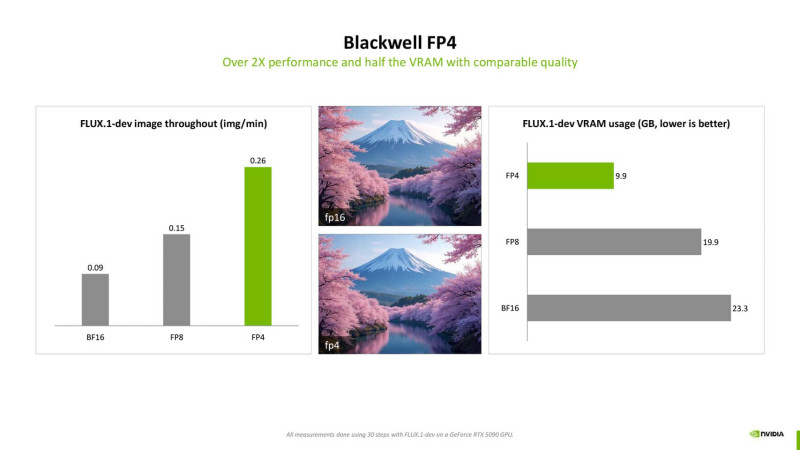
Blackwell масштабируется от дата-центров до игровых ноутбуков, предлагая разработчикам единый набор решений для оптимизации графики и производительности. В числе основных технологий — обучаемая генерация кадров, нейронное шумоподавление и FP4-вычисления, которые уменьшают нагрузку на память и ускоряют обработку данных. Обновлённая система Shader Execution Reordering распределяет задачи так, чтобы потоковые процессоры использовались максимально эффективно.
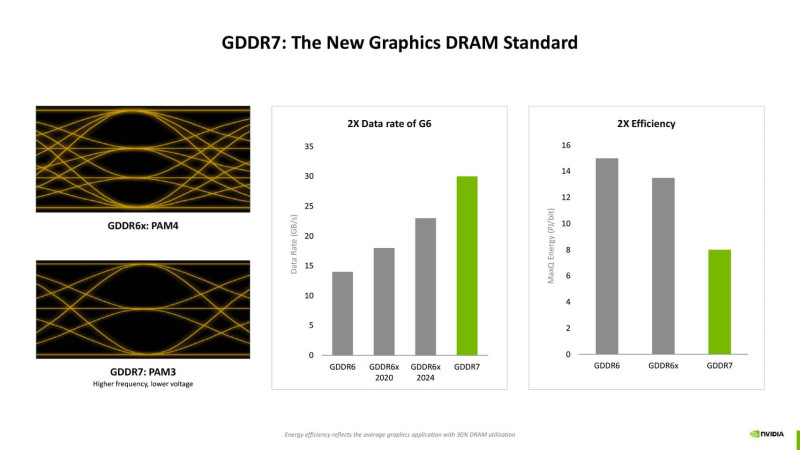
Поддержка GDDR7-памяти увеличивает пропускную способность при снижении энергопотребления, а встроенный AI-менеджер задач координирует работу графических шейдеров и нейросетевых моделей, сокращая задержки при смешанных нагрузках. Дополнительно внедрена концепция "race to idle", предполагающая интеллектуальную интерполяцию кадров вместо полного рендеринга, что позволяет снизить энергозатраты без потери качества изображения.
Ещё одно важное нововведение — Universal MIG, технология виртуализации, которая позволяет разделять один GPU на несколько виртуальных для облачных сервисов и лёгких игровых клиентов. Благодаря этим изменениям NVIDIA фактически формирует новый подход к разработке игр, где искусственный интеллект становится неотъемлемой частью графических технологий будущего.
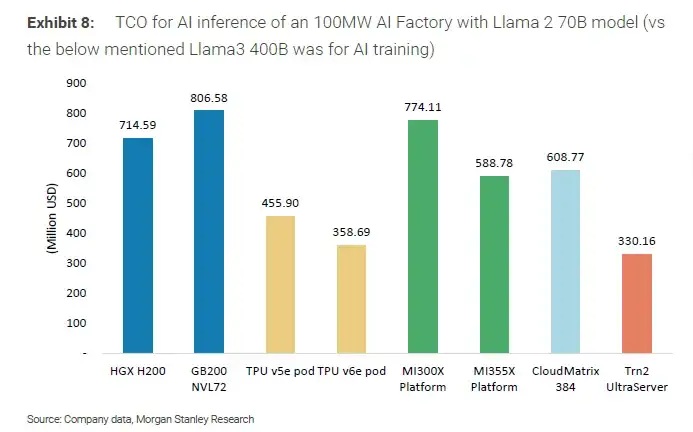
Аналитики Morgan Stanley опубликовали свежий отчёт о рентабельности ИИ-центров мощностью 100 МВт, показав, что NVIDIA GB200 NVL72 обеспечивают рекордную прибыльность, несмотря на самую высокую суммарную стоимость владения (TCO) среди всех протестированных платформ.
Каждый стойковый сервер GB200 NVL72 включает 72 GPU NVIDIA B200 и 36 CPU Grace, соединённые через высокоскоростной интерфейс NVLink 5. Стоимость одного такого кластера составляет около 3,1 млн долларов, что почти в 16 раз выше, чем у стойки на H100 (около 190 тыс. долларов).
По данным отчёта, прибыльность AI-центра при использовании GB200 NVL72 достигает 77,6%, что является лучшим показателем на рынке. На втором месте — Google TPU v6e pod с 74,9%, а замыкает тройку CloudMatrix 384 с более низким коэффициентом возврата инвестиций. При этом решения AMD MI300X и MI355X показали отрицательную маржу — –28,2% и –64% соответственно.
Однако рекордная прибыльность GB200 NVL72 достигается при самых высоких затратах: их TCO составляет 806,58 млн долларов, что выше, чем у всех конкурентов. Для сравнения, система на HGX H200 требует 714,59 млн, TPU v6e pod обходится в 455,9 млн, а Trn2 UltraServer — всего 330,16 млн.
Эксперты отмечают, что преимущество GB200 NVL72 обеспечивается сочетанием высокой производительности, энергоэффективности и оптимизации вычислений для reasoning-моделей и генеративных ИИ. Эти показатели делают платформу ключевым выбором для крупных дата-центров, работающих с моделями триллионного масштаба.
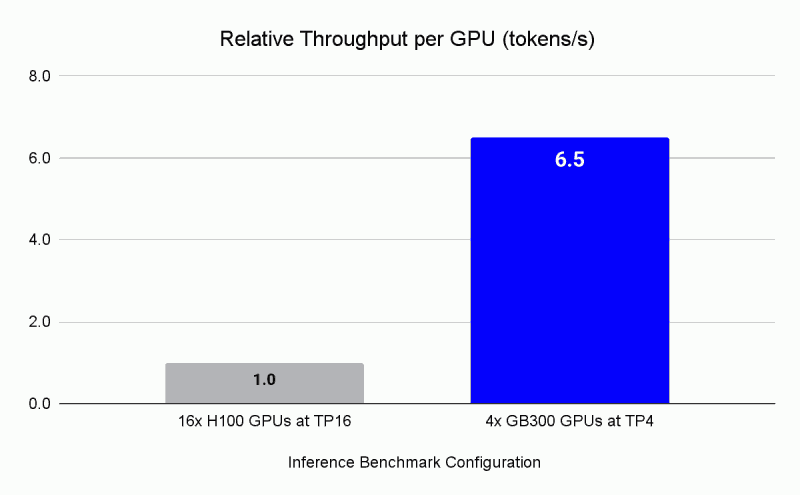
CoreWeave объявила о значительном скачке в производительности своих облачных ИИ-платформ, представив результаты тестов нового кластера на базе NVIDIA GB300 NVL72. В испытаниях, проведённых на модели DeepSeek R1, компания достигла 6,5-кратного прироста производительности по сравнению с решениями на NVIDIA H100, что стало возможным благодаря архитектурным улучшениям и увеличенной пропускной способности системы.
В ходе бенчмарков CoreWeave сравнила 16-GPU-систему на базе H100 с новой конфигурацией, использующей 4 GPU Blackwell Ultra в составе GB300 NVL72. Благодаря увеличенной памяти и высокой скорости обмена данными удалось перейти от 16-поточной параллельности (TP16) к 4-поточной (TP4), что резко снизило накладные расходы на коммуникацию между GPU. Результат — рост пропускной способности более чем в шесть раз и значительное ускорение генерации токенов для reasoning-моделей.
Система NVIDIA GB300 NVL72 создана для масштабных задач ИИ и включает 72 GPU Blackwell Ultra, соединённых пятого поколения NVLink с пропускной способностью 130 ТБ/с, а также 37 ТБ совокупной памяти для работы с моделями триллионного масштаба. Архитектура дополнена сетевой инфраструктурой NVIDIA Quantum-X800 InfiniBand, обеспечивающей равномерное распределение данных без узких мест.
Платформа CoreWeave интегрируется с Kubernetes и Slurm, используя интеллектуальный топологически-осведомлённый планировщик, который оптимизирует распределение задач внутри одного домена NVL72. В сочетании с системой мониторинга на базе Grafana это позволяет контролировать загрузку GPU, трафик NVLink и эффективность работы кластера в реальном времени.
Благодаря этим оптимизациям CoreWeave удалось обеспечить новый уровень производительности для reasoning-моделей, которые требуют сложной пошаговой логики. Сокращение задержек при инференсе открывает путь к созданию реальных ИИ-агентов, способных работать с большими данными и выполнять многошаговые вычисления в реальном времени.
NVIDIA представила обновления DLSS SDK версии 310.4.0 и Streamline SDK версии 2.9.0, сосредоточенные на улучшении стабильности и исправлении ошибок. Эти инструменты предназначены для разработчиков игр и приложений, позволяя интегрировать технологии масштабирования, генерации кадров и другие возможности, основанные на алгоритмах искусственного интеллекта.
DLSS SDK 310.4.0 служит основой для таких функций, как DLSS Super Resolution и DLAA (Deep Learning Anti-Aliasing). Новый релиз включает в себя обновления, направленные на повышение качества изображения, исправление проблем с артефактами, включая призраки и мигание в динамичных сценах. Поддержка интеграции обеспечивается через NGX API, что позволяет разработчикам проще добавлять функции в свои проекты.
Streamline SDK 2.9.0 также обновился и остаётся предпочтительным инструментом для интеграции DLSS 4 и других технологий NVIDIA. Обновлённый фреймворк поддерживает DLSS Super Resolution, Multi-Frame Generation, Ray Reconstruction, NVIDIA Reflex и Image Scaling. Несмотря на отсутствие крупных нововведений, новые исправления багов и оптимизация стабильности позволяют ускорить разработку и упрощают внедрение функций.
NVIDIA рекомендует разработчикам заменить старые бинарные файлы, заголовки и плагины на обновлённые версии и провести проверку всех доступных режимов DLSS: Quality, Balanced, Performance и Ultra Performance. Это обеспечит корректную работу технологий в проектах нового поколения и оптимизирует качество изображения на различных платформах.
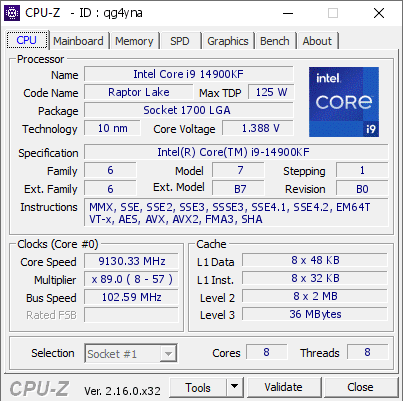
Intel Core i9-14900KF стал самым быстрым процессором в мире, установив новый мировой рекорд по частоте. Китайский оверклокер wytiwx разогнал чип до 9 130,33 МГц с использованием жидкого гелия, что официально зафиксировано базой HWBot.
До этого долгое время лидерство принадлежало AMD, особенно модели FX-8370, которая удерживала рекорд целых девять лет после достижения 8,722 ГГц в 2014 году. Однако с появлением архитектуры Raptor Lake и её обновления Raptor Lake Refresh пальма первенства перешла к Intel. Последним рекордсменом был Core i9-14900KS, но 14900KF превзошёл его на 13 МГц, заняв вершину рейтинга.
Для разгона использовалась материнская плата ASUS ROG Maximus Z790 Apex, одна планка памяти Corsair Vengeance DDR5 объёмом 32 ГБ на частоте DDR5-5744, видеокарта GeForce RTX 3050 и блок питания Corsair HX1200i. Процессор питался напряжением 1,388 В, а экстремальное охлаждение жидким гелием обеспечило стабильность на рекордной частоте.
AMD раскрыла подробности о Pensando Pollara 400 AI NIC на конференции Hot Chips 2025 — первой в индустрии сетевой карте, готовой к стандарту UEC (Ultra Ethernet Consortium). Устройство ориентировано на AI-системы и предлагает пропускную способность 400 Гбит/с, что соответствует возможностям NVIDIA ConnectX-7, но при этом дополняет экосистему решений AMD для ЦОД и генеративного ИИ.
Pensando Pollara 400 AI NIC построена на архитектуре P4 и обеспечивает до 1,25-кратного прироста производительности, сокращение времени выполнения задач и поддержку RDMA. Сетевая карта использует интерфейс PCIe Gen5 x16 и интегрируется с решениями AMD EPYC и Instinct без необходимости во внешних PCIe-коммутаторах.
Ключевыми особенностями стали программируемый конвейер обработки данных, атомарные операции с памятью, оптимизированная согласованность кэша и система виртуального преобразования адресов (va2pa). Эти улучшения обеспечивают более высокую эффективность при работе с нагрузками ИИ и повышают отказоустойчивость инфраструктуры. AMD позиционирует новую карту как часть единой экосистемы, создавая фундамент для будущих 400GbE и 800GbE решений в дата-центрах.
Компания NVIDIA анонсировала новое поколение своей встраиваемой платформы Jetson Thor, созданной на базе архитектуры Blackwell и ориентированной на развитие гуманоидных роботов и систем Physical AI. Решение выводит вычислительные возможности на новый уровень, предлагая огромный прирост производительности по сравнению с предыдущим поколением Jetson Orin и открывая путь к созданию более автономных и интеллектуальных машин.
В основе платформы лежит модуль Jetson T5000, оснащённый 14 ядрами Arm Neoverse-V3AE, а также 2560-ядерным GPU на архитектуре Blackwell с 96 тензорными ядрами пятого поколения. NVIDIA заявляет о 7,5-кратном росте вычислительной мощности ИИ, 3,1-кратном увеличении производительности CPU и двукратном расширении памяти. Система получила 128 ГБ LPDDR5X с пропускной способностью 273 ГБ/с и интегрированное хранилище 1 ТБ NVMe.
Общая вычислительная мощность достигает 2070 терафлопс FP4 при энергопотреблении до 130 Вт, что делает Jetson Thor оптимальной платформой для управления роботами нового поколения. Поддерживается современная система ввода-вывода, включая HDMI, DisplayPort, USB-A 3.2, USB-C 3.1, Gigabit Ethernet, а также QSFP28 с поддержкой 100 GbE.
По данным NVIDIA, компании Agility Robotics и Boston Dynamics уже начали интеграцию Jetson Thor в свои продукты, а Foxconn готовит выход собственных гуманоидных роботов до конца года. Стоимость комплекта разработчика Jetson AGX Thor составляет $3 499, что делает решение дорогим, но при этом одним из самых продвинутых на рынке робототехники.
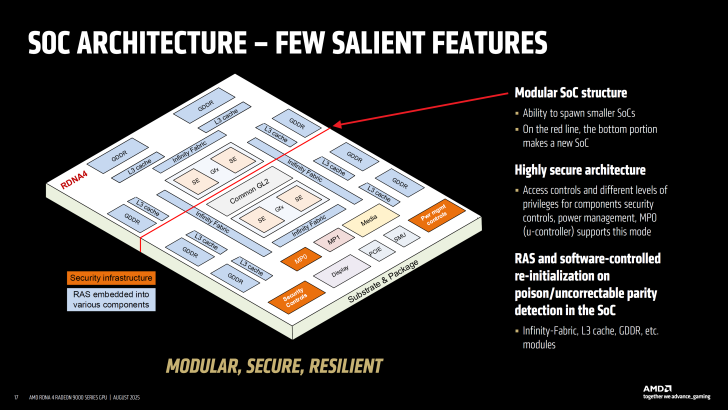
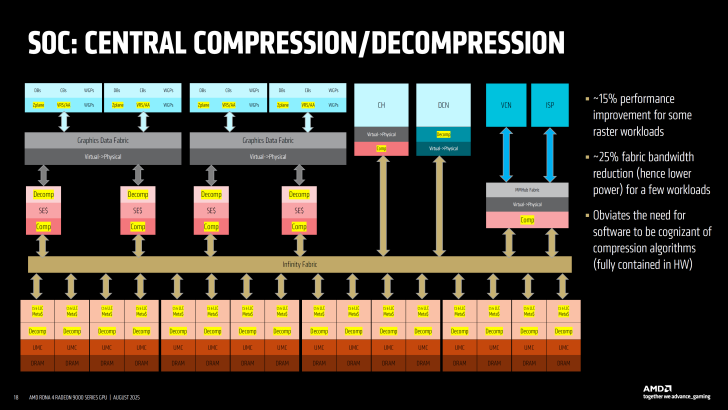
На конференции Hot Chips 2025 компания AMD представила новые подробности о своей графической архитектуре RDNA 4 и модульном дизайне SoC, который лежит в основе будущих видеокарт серии Radeon RX 9000. Главные акценты сделаны на оптимизации производительности, гибкой конфигурации SoC и новых технологиях сжатия данных, повышающих эффективность чипов.
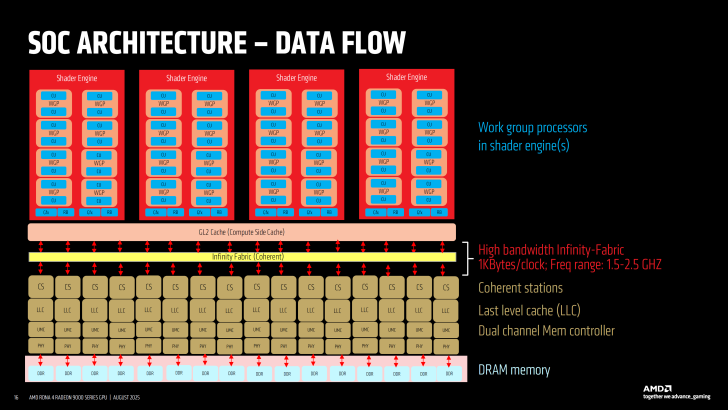
Архитектура RDNA 4 построена как модульная SoC-платформа, что позволяет масштабировать конфигурации для разных серий продуктов — от компактных решений до топовых видеокарт. Базовая схема использует Shader Engines (SE), каждый из которых включает несколько Work Group Processors (WGP) с двумя Compute Units на каждый. Взаимодействие с контроллерами памяти осуществляется через улучшенный GL2 Cache и обновлённую Infinity Fabric, обеспечивающую пропускную способность 1 КБ/так при частоте от 1,5 до 2,5 ГГц.
Модульность RDNA 4 даёт AMD возможность гибко масштабировать конфигурации. Например, чип Navi 44 оснащён двумя Shader Engines и четырьмя контроллерами GDDR6 (128-бит), тогда как топовый Navi 48, используемый в Radeon RX 9070 XT, получает больше Shader Engines, увеличенный L3-кэш и дополнительные линии Infinity Fabric для расширенной пропускной способности.
AMD также представила обновлённые алгоритмы центрального сжатия и распаковки данных. Благодаря этому производительность в растеризационных задачах повышается до 15%, а нагрузка на внутреннюю шину сокращается на 25%, что снижает энергопотребление и улучшает тепловые характеристики. При этом вся логика компрессии реализована на аппаратном уровне, не требуя изменений в драйверах или софте.
RDNA 4 поддерживает четыре уровня "урезания" чипов для создания разных SKU: SE Harvest позволяет сокращать Shader Engines, WGP Harvest регулирует количество процессорных блоков, Asymmetric Harvest перераспределяет ресурсы между задачами, а Memory Device Harvest управляет отдельными каналами GDDR6. На данный момент AMD представила четыре SKU на базе Navi 48 и три SKU на Navi 44, но модульный подход SoC открывает путь для будущих кастомных решений и более производительных конфигураций в рамках RDNA 4 и последующих поколений.
Инженер и дата-сайентист Сэм Уилкинсон решил построить «мышь, которую Logitech не делает», переделав популярный трекбол Logitech MX Ergo. Он установил порт USB‑C, заменил шумные микропереключатели и нашёл лёгкое альтернативное ПО. Однако проект неожиданно превратился в дорогой эксперимент: оказалось, что в 2024 году Logitech уже выпустила обновлённую модель MX Ergo S, исправившую большинство недостатков оригинала.
Первоначально Уилкинсон критиковал старую версию MX Ergo за использование устаревшего micro‑USB, громкие микросвитчи и «тяжёлое» ПО Logi Options+. Он заказал кастомную плату с USB‑C за $55, купил профессиональную паяльную станцию за $200 и установил тихие Huano Silent Switches, которые обошлись всего в $2.99. В результате трекбол получил почти бесшумные клики и современный разъём.
Для настройки Уилкинсон отказался от стандартного ПО Logitech, выбрав лёгкую и совместимую с большинством устройств утилиту SteerMouse за $20. В итоге стоимость модификаций составила $277.99, что более чем в два раза превышает цену новой модели MX Ergo S. Иронично, что выпущенный Logitech в 2024 году MX Ergo S уже имеет порт USB‑C, тихие переключатели и стоит всего на $20 дороже оригинальной версии. Тем не менее, Уилкинсон признаёт, что проект дал ему полезный опыт работы с пайкой и позволил улучшить устройство, даже если финансово это решение оказалось спорным.
На конференции Hot Chips 2025 компания NVIDIA представила новые подробности об архитектуре Blackwell RTX, лежащей в основе видеокарт GeForce RTX 5090 и RTX PRO 6000. Главный акцент сделан на нейронном рендеринге и инновациях для игр, которые стали возможны благодаря мощному сочетанию новых Tensor Cores, RT-ядер и улучшенной энергоэффективности.
Согласно презентации, RTX Blackwell предлагает до 4000 AI TOPS за счёт 5-го поколения Tensor Cores с поддержкой FP4, до 360 RT TFLOPs с 4-м поколением RT-ядер и пропускную способность памяти до 30 Гбит/с благодаря GDDR7. Архитектура также получила поддержку PCIe 5.0, DisplayPort 2.1 UHBR20, а также четыре модуля NVENC/NVDEC с кодированием 4:2:2, что расширяет возможности по работе с видео и высокими разрешениями.
Одним из ключевых нововведений стала технология DLSS 4, которая использует Multi Frame Generation (MFG) и позволяет ИИ генерировать 100% пикселей после построения исходного кадра. Это обеспечивает значительное ускорение рендеринга, сокращает энергопотребление и увеличивает автономность на мобильных устройствах. В сочетании с обновлённой системой Shader Execution Reordering (SER) производительность выросла до 2 раз по сравнению с предыдущим поколением.
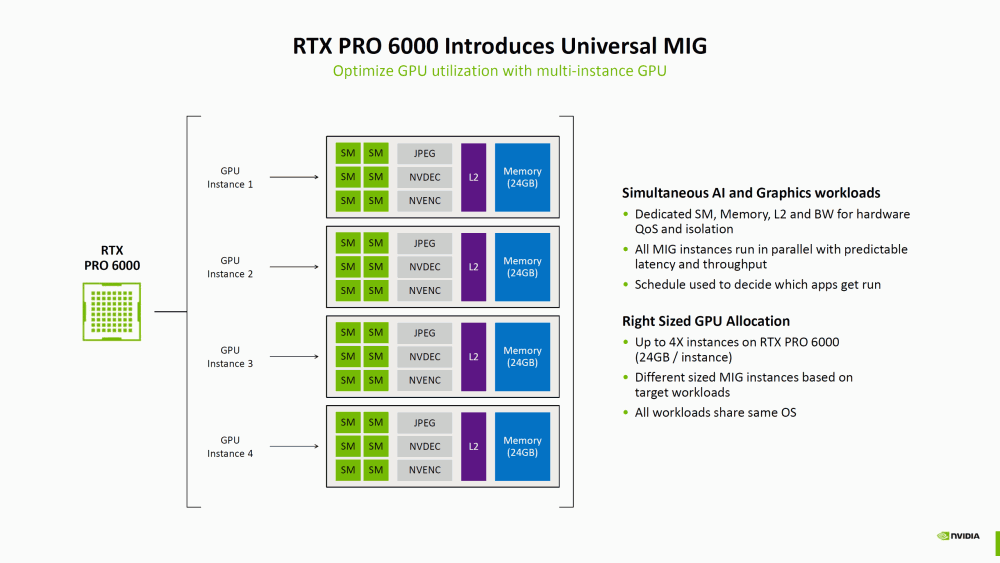
Отдельное внимание уделено профессиональному сегменту: видеокарта RTX PRO 6000 получила поддержку Universal MIG, позволяя разделять GPU на четыре независимых экземпляра с 24 ГБ VRAM каждый. На демонстрации четыре копии Cyberpunk 2077 запускались одновременно в 1080p при максимальных настройках, а масштабируемость в режиме MIG 4x обеспечила прирост производительности до 60%.