GeForce RTX 5060 Ti была замечена на полке Walmart с ценником в $240, что существенно ниже текущей рыночной стоимости. Судя по наклейке с двойной скидкой, это уценённая видеокарта, возможно, из-за возврата, открытой упаковки или внутренней распродажи.
RTX 5060 Ti относится к новому поколению видеокарт среднего сегмента, однако даже в США её цена редко опускается ниже $300. Поэтому такая находка вызвала ажиотаж среди пользователей — многие считают, что именно такие цены должны быть нормой для массовых решений.
Пользователь Reddit, опубликовавший фото, отметил, что карта станет заменой его GTX 1060. В обсуждениях ему посоветовали собрать систему на базе Ryzen 7600X или 5700X3D, что обеспечит сбалансированный апгрейд. AM5-платформа постепенно дешевеет, что делает такие сборки ещё привлекательнее.
Сама по себе уценка RTX 5060 Ti не говорит о масштабных скидках, но может быть сигналом начала перераспределения складов перед выходом новых моделей. При этом даже единичный случай с ценой в $240 демонстрирует, что доступные GPU всё ещё можно найти, пусть и не всегда в идеальном состоянии.
Владелец видеокарты MSI RTX 5090 Ventus 3X столкнулся с серьёзными проблемами, закончившимися перегоранием 12-pin кабеля питания. История, опубликованная на Reddit, охватывает несколько месяцев нестабильной работы системы, начиная с чёрных экранов, мерцаний и сбоев драйвера — и заканчивая полным отказом видеокарты.
После первых проблем с драйверами пользователь провёл полную очистку системы с помощью DDU, что частично решило проблему. Однако сбои продолжились, и после обновления BIOS материнской платы видеокарта вообще перестала определяться, несмотря на отсутствие встроенной графики в процессоре Core i9-12900KF. Новый драйвер Nvidia помог лишь временно — при запуске игр GPU полностью отключалась, оставляя оба монитора без сигнала.
Многонедельные попытки диагностики и устранения неполадок — от исследования дампов памяти до анализа температуры, напряжения и версий BIOS — не дали результата. Проблема казалась программной до последнего момента. Только когда пользователь решился физически снять карту и проверить соединение, выяснилось, что коннектор 12VHPWR был обуглен и оплавлен.
Этот случай поднимает вопросы надёжности разъёма 12VHPWR даже в флагманских решениях вроде RTX 5090, несмотря на многочисленные меры по устранению прежних проблем с подобными инцидентами в RTX 4090. Пользователь сообщил, что кабель был подключён правильно, без натяжения или деформации, и не подвергался нагрузке. Сейчас владелец видеокарты оформляет RMA через MSI, надеясь на благополучную замену устройства.
RTX 5090 остаётся крайне мощным, но чувствительным к качеству и состоянию питания устройством, и даже минимальные отклонения в подключении могут привести к критическим последствиям.
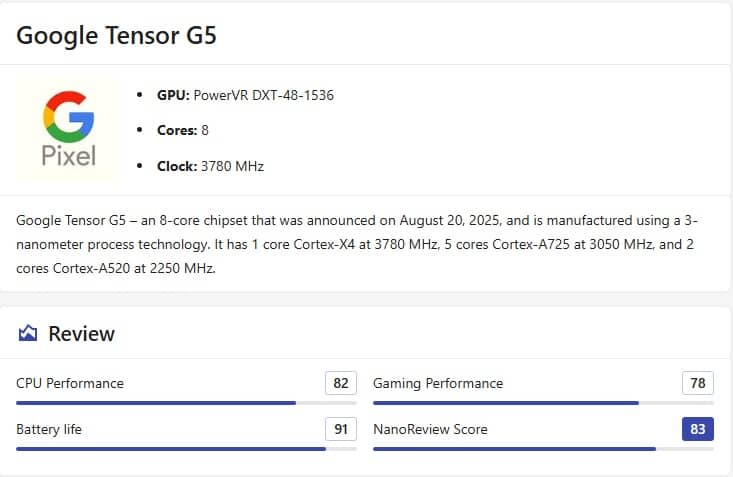
Процессор Tensor G5, установленный в Pixel 10, оказался проблемным — пользователи и энтузиасты жалуются на быстрое перегревание и агрессивный троттлинг, особенно в играх и при эмуляции. При этом, несмотря на переход на современный 3-нм техпроцесс TSMC, архитектура чипа вызывает множество вопросов.
Конфигурация CPU включает 1 ядро Cortex-X4 с частотой 3.78 ГГц, 5 ядер Cortex-A725 на 3.05 ГГц и 2 энергоэффективных Cortex-A520 на 2.25 ГГц. Графическая часть — GPU Imagination IMG DXT-48-1536, теоретически сравнимый с Adreno 732/740 и Mali G715 MP7, но без поддержки трассировки лучей. В составе также присутствует 5-е поколение TPU для ИИ-задач и модем Exynos 5G.
Проблема, как отмечают специалисты, не в частотах и не в GPU Imagination, а в разрозненности всей архитектуры. Google использует готовые ядра от Arm, тогда как, например, Snapdragon 8 Gen 5 Elite основан на кастомных ядрах Oryon, достигающих 4.60 ГГц и оснащённых продвинутым L2-кэшем объёмом 12 МБ. Это даёт мощный прирост производительности, особенно в длительной нагрузке.
Дополнительную сложность вносит и сотрудничество с Imagination Technologies. Google не имеет доступа к драйверам на низком уровне, что ограничивает возможности тонкой оптимизации, особенно в GPU-нагруженных сценариях.
Таким образом, стратегия Google — «собрать из готового» — даёт результат, который выглядит актуально на бумаге, но не выдерживает конкуренции с кастомными решениями от Qualcomm. Пока Google продолжает подходить к созданию чипов фрагментарно, её процессоры будут уступать в производительности, даже несмотря на прогрессивные технологии вроде TPU.
Компания Nvidia представила уникальный проект в рамках GeForce Garage — полноценный игровой ПК, встроенный в колесо от Porsche. Автор модификации — известный кастомайзер Justin Chu (JCustom), а заказчиком выступил актёр и геймер Michael Rainey Jr., звезда сериала Power.
В качестве базы использовался диск HRE FF21 стоимостью от $750. Он был перекрашен в фирменный оттенок Python Green, чтобы соответствовать цвету Porsche 911 Turbo S владельца. Материнская плата ROG Maximus Z890 Hero и RTX 5080 установлены прямо за спицами, а всё оборудование скрыто в специально изготовленном толстом поддоне, закреплённом внутри обода. Благодаря обратному подключению кабелей и LED-подсветке по периметру создаётся эффект парящей сборки.
Особое внимание уделено охлаждению: вся жидкостная система размещена в отдельной секции под колесом, соединённой с ПК через быстросъёмные фитинги. Водоблок CPU не имеет внешних трубок — жидкость проходит через его крепления, а блок GPU украшен вращающимся индикатором потока и миниатюрной копией трофея NAACP, которым награждён актёр.
Интересная деталь — включение ПК через реальный брелок от Porsche, а дисплей в центре диска показывает телеметрию и анимации. Вся подставка окрашена в Python Green и обтянута алькантарой, создавая премиальный образ. При этом ПК показал впечатляющие результаты в играх: 200 FPS в Forza Horizon 5, до 180 FPS в Borderlands 3 и до 170 FPS в Cyberpunk 2077 с трассировкой пути.
Проект стал не только эстетическим объектом, но и мощной системой на базе Intel Core Ultra 9 285K, 32 ГБ DDR5-7200 и трёх NVMe-дисков по 2 ТБ, в корпусе, который одновременно является арт-объектом и символом объединения автомобильной и игровой культур.
MediaTek усиливает позиции в топовом сегменте мобильных процессоров, сохраняя при этом конкурентное ценообразование. Согласно последним данным, Dimensity 9500 обойдётся производителям в $180–200, что делает его самым дорогим чипом в истории компании. Однако он всё ещё дешевле, чем Snapdragon 8 Gen 5 Elite, стоимость которого для OEM-партнёров достигает $280.
Новые процессоры MediaTek демонстрируют устойчивый рост цен. Dimensity 9400 оценивается в $155, а его улучшенная версия Dimensity 9400+ — уже в $165–175. Это ощутимый шаг вперёд по сравнению с Dimensity 9300 ($120–130) и 9300+ ($130–145), что отражает рост сложности архитектуры и переход на более современные техпроцессы.
При этом MediaTek сохраняет сбалансированный подход — предлагая топовую производительность и расширенные функции, включая передовые блоки ИИ и поддержку новейших стандартов связи, по более доступной цене, чем у конкурентов. Даже Dimensity 9500, с максимальной стоимостью в $200, заметно дешевле ближайшего аналога от Qualcomm.
Важно подчеркнуть, что окончательные закупочные цены зависят от контрактов, объёмов поставок и условий эксклюзивности. Тем не менее, текущие оценки дают чёткое понимание стратегии MediaTek — захватить долю в премиум-классе без агрессивного завышения цен.
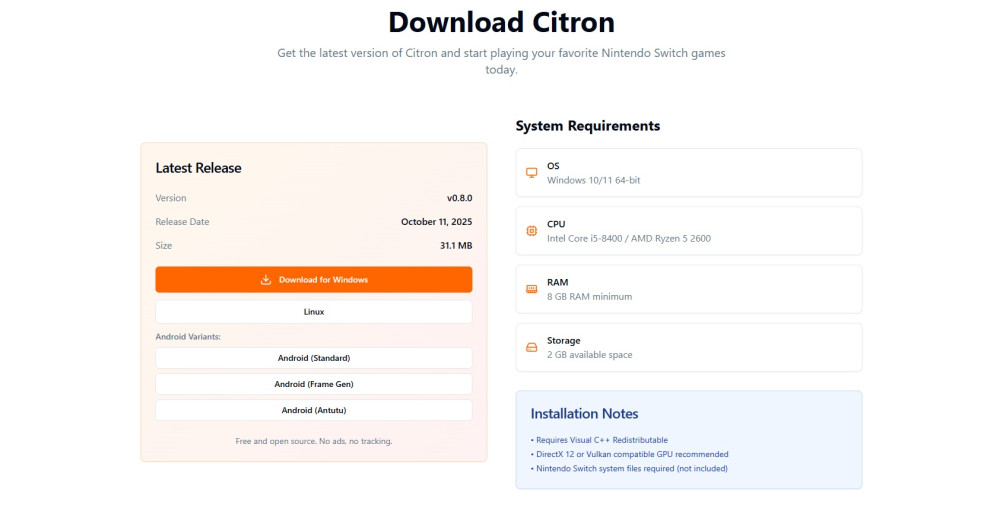
Вышла новая версия эмулятора Nintendo Switch — Citron 0.8.0, которая приносит долгожданную поддержку последних версий The Legend of Zelda: Breath of the Wild (v1.8.2) и Tears of the Kingdom (v1.4.2). Разработчики устранили критические ошибки, вызывавшие бесконечные загрузки и сбои при определении контроллеров, особенно в играх, построенных на базе SDK20.
Ключевым техническим достижением стало внедрение полноценной поддержки аудиосистемы REV15 с нативной обработкой звука в формате с плавающей запятой. Это повысило качество и стабильность звука, устранив треск и обеспечив совместимость с современными аудиодвижками. Особенно это заметно в проектах, использующих последние версии SDK Nintendo.
В обновлении также появились новые визуальные фильтры: ScaleFX — для улучшения изображения в пиксель-арт играх, и Lanczos — для качественного ресемплинга. Кроме того, добавлен экспериментальный режим рендеринга в 0.25X разрешении, предназначенный для повышения производительности на слабом оборудовании, особенно на Android-устройствах.
Значительный шаг в оптимизации — внедрение сборок с использованием Profile-Guided Optimization (PGO). Эта технология анализирует поведение во время игры и позволяет увеличить производительность до 30% при повторной компиляции. Также реализованы оверлеи мониторинга температуры CPU/GPU и уровня заряда батареи.
Разработка версии 0.8.0 стала возможной благодаря сотрудничеству с несколькими проектами: форком Ryujinx под названием Ryubing, менеджером модов TKMM и фреймворком NX Optimizer. Это делает Citron одной из самых активно развивающихся платформ для эмуляции Switch-игр.
Библиотека Кембриджского университета открыла двери для всех, у кого осталась старая дискета с забытым содержимым. Акция «Copy that Floppy» стала первым шагом проекта Future Nostalgia — годичной инициативы по спасению информации с устаревших магнитных носителей, которые уже почти не читаются.
Цель проекта — извлечь данные с дискет до того, как время и деградация покрытия сделают это невозможным. В коллекциях библиотеки хранится более 150 таких носителей: от черновиков научных работ и архивов Стивена Хокинга до личных файлов и уникального программного обеспечения. Основная проблема — даже если дискета ещё работает, найти рабочее оборудование для чтения становится всё сложнее.
Проект возглавляет команда цифровой консервации, работающая в сотрудничестве с сообществом ретро-компьютинга. Вместо дешёвых USB-приводов они используют профессиональные решения — KryoFlux и Greaseweazle, которые считывают сигнал на уровне магнитного потока, позволяя восстанавливать файлы даже с повреждённых или нестандартных дискет.
Future Nostalgia также стремится создать стандартизированный и прозрачный рабочий процесс, который смогут использовать другие архивы и музеи. После извлечения информации архивисты сталкиваются со второй проблемой — распознаванием забытых форматов и проприетарных редакторов, вроде WordPerfect и BASIC, для которых уже нет актуального ПО.
Компания MSI выпустила специальную версию видеокарты GeForce RTX 5080 Gaming Trio, оформленную в стиле шутера Battlefield 6. Устройство получило уникальный дизайн в фирменных цветах игры, а также тематическую упаковку с логотипами серии. Производитель также объявил, что часть этих видеокарт будет разыграна бесплатно среди фанатов.
Модель основана на стандартной RTX 5080 в исполнении Gaming Trio — это флагманская трёхвентиляторная система охлаждения, фирменная подсветка и усиленная плата питания. В версии Battlefield 6 Edition карта визуально отличается оформлением кожуха и бэкплейта: корпус окрашен в серо-синий камуфляж с контрастными акцентами, отсылающими к ключевым элементам новой игры.
Акция организована в честь успешного запуска Battlefield 6, который стал самым популярным релизом EA на ПК: более 700 тысяч одновременных игроков в Steam. MSI использует эту волну интереса, чтобы привлечь внимание к своей линейке RTX 50-й серии. Участники смогут получить видеокарту, выполнив простые условия, включая подписку на официальные страницы MSI и Battlefield.
Ранее в этом году MSI уже выпускала лимитированные видеокарты с оформлением в стиле игр, включая Diablo IV и Starfield, но вариант с Battlefield 6 стал первой моделью на базе RTX 5080, получившей тематический редизайн.
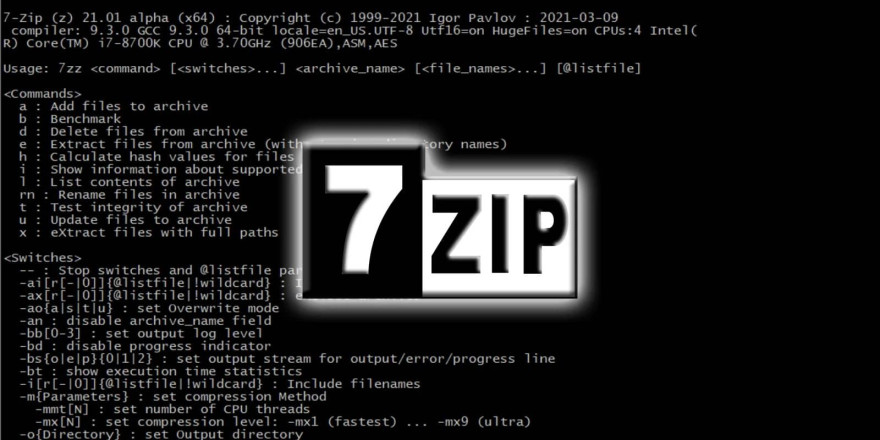
В архиваторе 7-Zip обнаружены две опасные уязвимости, которые позволяют выполнять произвольный код при открытии специально созданного ZIP-файла. Проблемы были зафиксированы специалистами Zero Day Initiative и обозначены как CVE-2025-11001 и CVE-2025-11002. Хотя патч вышел ещё в июле в версии 7-Zip 25.00, подробности стали известны только сейчас — в октябре.
Уязвимости связаны с неправильной обработкой символьных ссылок внутри ZIP-архивов. Злоумышленник может создать файл, при извлечении которого происходит выход за пределы целевой директории и запись данных в произвольные участки системы. Это открывает путь для запуска вредоносного кода от имени текущего пользователя. Обе уязвимости получили оценку 7.0 по CVSS, что соответствует высокому уровню риска.
Для атаки требуется минимальное взаимодействие — достаточно просто открыть или распаковать вредоносный архив. Далее используется механизм обхода директорий и подмена файлов в чувствительных местах, что в сочетании может привести к полному захвату среды Windows, особенно если архив открывает привилегированный сервисный процесс.
Особую опасность ситуация представляет из-за отсутствия автоматического обновления в 7-Zip. Пользователи, особенно в корпоративных системах с устаревшими портативными версиями, могут годами оставаться на уязвимом билде. Версия 25.00 устраняет данные проблемы, а актуальный стабильный выпуск — 25.01, вышедший в августе.
Если вы не обновлялись с лета, немедленно установите свежую версию с официального сайта проекта. Пока обновление не выполнено, рекомендуется не открывать ZIP-архивы из ненадёжных источников.
В Китае произошёл курьёзный случай, быстро ставший вирусным в игровом сообществе. Во время свадебной церемонии невеста преподнесла жениху подарок — видеокарту NVIDIA GeForce RTX 5090, стоимостью около $3000, прямо в руках, на глазах у гостей. Момент вызвал бурю эмоций у публики и был заснят на видео.
На кадрах видно, как жених получает коробку с флагманской RTX 5090 от ASUS, а невеста сияет от радости, в то время как гости аплодируют и смеются. Пользователи соцсетей мгновенно распространили снимки, а геймерские форумы окрестили это «идеальной парой» и «брачным контрактом, подписанным DLSS и 32 ГБ GDDR7».
История с видеокартой на свадьбе стала ещё одним напоминанием, насколько глубоко геймерская культура интегрировалась в повседневную жизнь, вплоть до самых трогательных и символичных моментов. Теперь видеокарта — это не просто техника, а выражение любви, понимания и уважения к хобби партнёра.