




NVIDIA запускает TensorRT-LLM для оптимизации работы больших языковых моделей на своих GPU
NVIDIA представила новую программную платформу TensorRT-LLM, разработанную для ускорения работы с большими языковыми моделями на видеокартах компании. Отметим, что программа TensorRT-LLM будет поддерживаться всеми современными GPU от NVIDIA, включая такие модели как A100, H100 и многие другие.
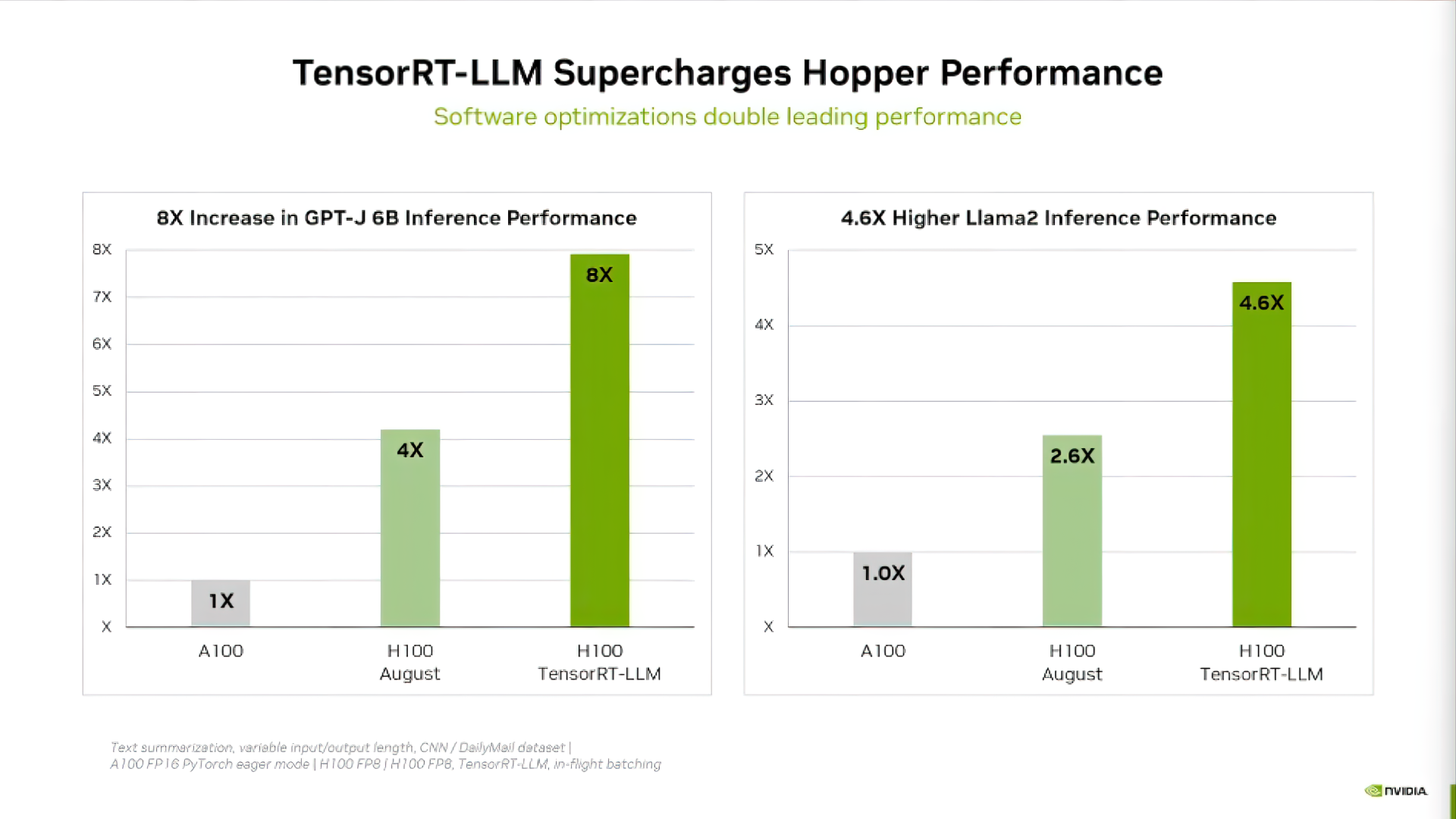
Эта платформа позволяет значительно улучшить производительность языковых моделей благодаря ряду нововведений. Одним из ключевых обновлений стал новый планировщик In-Flight batching, который делает работу GPU более эффективной, позволяя обрабатывать несколько запросов одновременно.
Кроме того, TensorRT-LLM оптимизирована для работы на графических процессорах Hopper и предлагает функции автоматической конвертации FP8, компилятор DL для объединения ядер и оптимизатор смешанной точности.
По данным NVIDIA, использование TensorRT-LLM позволило удвоить производительность GPU H100 в тесте GPT-J 6B и увеличить ее до 5 раз в тесте Llama2. Стоит отметить, что компания активно сотрудничает с крупнейшими разработчиками, такими как Meta и Grammarly, для ускорения их языковых моделей с помощью TensorRT-LLM.