




NVIDIA ускоряет вывод результатов на Llama 3.1 до 1.9x благодаря новому алгоритму Medusa для HGX H200
NVIDIA продолжает улучшать свою программную экосистему, представив новый алгоритм Medusa для ускорения работы ИИ-моделей Llama 3.1 на своих ускорителях HGX H200. Этот инновационный алгоритм, использующий технику "спекулятивного декодирования", помогает увеличить скорость генерации токенов до 1.9x, что обеспечивает высокую производительность при работе с большими языковыми моделями.
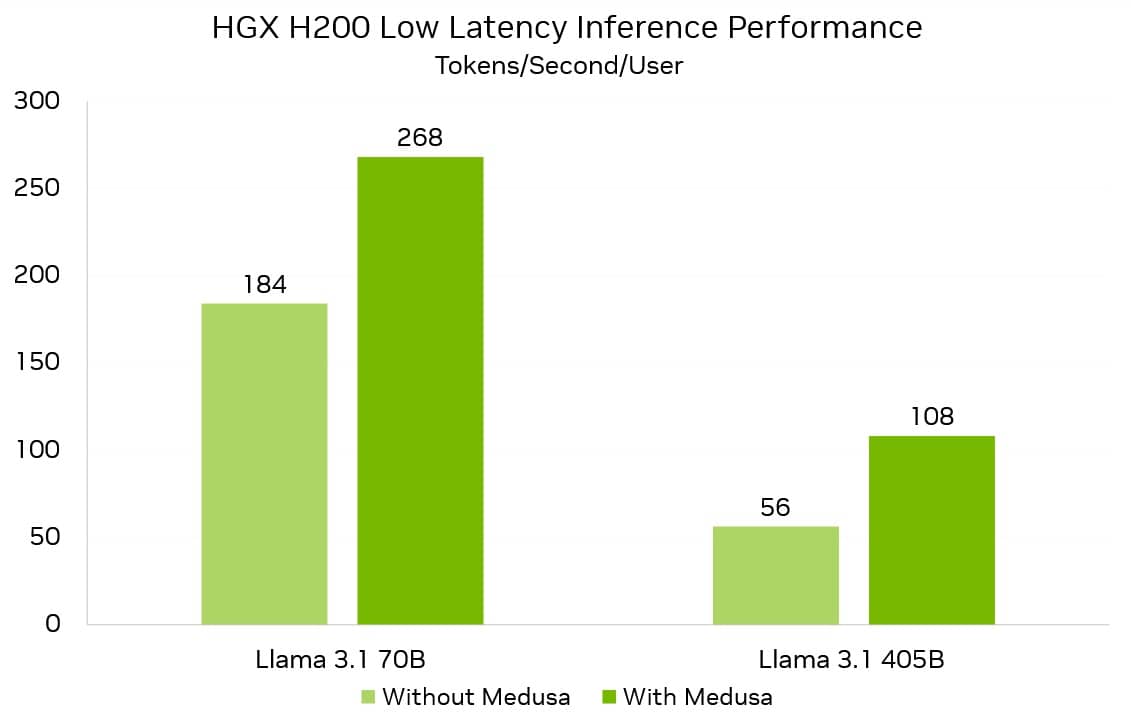
С помощью Medusa, сервера NVIDIA HGX H200 с восемью GPU H200 Tensor Core могут достигать скорости генерации 268 токенов в секунду на Llama 3.1 70B и 108 токенов на Llama 3.1 405B. Это значительно ускоряет взаимодействие с моделями, где каждая GPU обменивается данными через NVLink Switch на скорости 900 ГБ/с. Такая архитектура позволяет избежать узких мест в коммуникации между GPU и обеспечивает высокую производительность.
Технология TensorRT-LLM, интегрированная с Medusa, оптимизирует использование параллельных вычислительных ресурсов GPU, что делает возможной более эффективную генерацию токенов. NVIDIA продолжает инновации во всех аспектах своей технологии, что обеспечивает лидирующие позиции компании на рынке решений для ИИ.