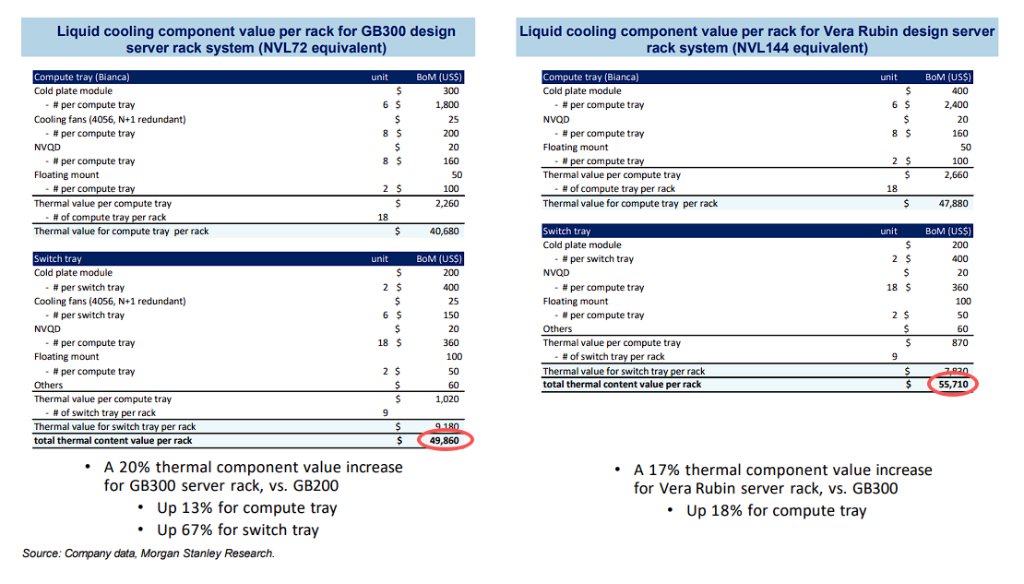
Аналитики из Morgan Stanley опубликовали отчет, в котором подробно разбирается стоимость компонентов жидкостного охлаждения для серверных стоек Nvidia. Согласно их данным, общая стоимость «термальных компонентов» для одной серверной стойки текущего поколения GB300 (NVL72) составляет $49,860. Эта цифра сама по себе уже включает 20% рост стоимости по сравнению с предыдущей платформой GB200.
Однако с выходом следующего поколения ИИ-ускорителей тенденция к удорожанию сохранится. По прогнозам, для платформы Vera Rubin (NVL144) общая стоимость... $55,710 за одну стойку. Это представляет собой дополнительный 17% рост по сравнению с GB300.
Основным драйвером удорожания станут вычислительные лотки (compute tray). В отчете указано, что стоимость охлаждения для 18 таких лотков в стойке Vera Rubin вырастет до $47,880 (по $2,660 за лоток) по сравнению с $40,680 (по $2,260 за лоток) в поколении GB300. Это составляет 18% рост именно в этой категории.
Любопытно, что стоимость компонентов охлаждения для коммутационных лотков (switch tray) при этом, наоборот, снизится. Согласно таблице, общая стоимость для 9 лотков-коммутаторов в стойке Vera Rubin составит $7,830 ($870 за лоток), что заметно меньше по сравнению с $9,180 ($1,020 за лоток) в системе GB300.
В состав компонентов охлаждения, учтенных в отчете, входят холодные пластины (cold plate modules), вентиляторы, компоненты NVQD и различные монтажные крепления. Рост общей стоимости подчеркивает растущую сложность управления тепловыделением в будущих поколениях ИИ-ускорителей, которые требуют все более дорогих инженерных решений.
MSI представила свою новую флагманскую материнскую плату MEG X870E ACE MAX для платформы AM5, которая станет самой мощной в линейке ATX-формата. Эта модель относится к топовому классу ACE, ранее представленному на платформах X670E и Z890, и сочетает в себе продвинутые функции для энтузиастов разгона, улучшенную BIOS и премиальный дизайн.
Среди ключевых особенностей — схема питания 18+2+1 с 110-амперными фазами, двойной 8-контактный разъём питания CPU, а также фирменный OC Engine — встроенный генератор тактов, позволяющий добиться до 15% прироста производительности. Дополнительно реализован Direct OC Jumper для моментальной настройки BCLK в реальном времени.
Новая BIOS ёмкостью 64 МБ обеспечит поддержку будущих обновлений UEFI, включая линейку AMD Ryzen 3D V-Cache нового поколения, среди которых ожидаются модели с двойными CCD. Также заявлена система Illusion Lightning с уникальной подсветкой на передней панели и логотипом MSI Dragon.
На плате размещены пять слотов M.2, из которых два — с поддержкой PCIe 5.0, и все они охлаждаются системой Shield Frozr с магнитным креплением или быстрой клипсой. Верхний слот PCIe 5.0 x16 использует EZ PCIe Release для облегчения замены GPU. Система охлаждения построена на прямом контакте с тепловой трубкой и пластинами с волнообразными рёбрами, с применением термопрокладок 9 Вт/м·К и металлической задней панели.
Плата также предлагает 10GbE-сеть, поддержку Wi-Fi 7, порты USB 40G, дополнительный 8-контактный разъём для питания PCIe и двойные PCIe 5.0 x16 слоты. Официальный старт продаж ожидается ближе к CES 2026, а первые поставки уже начались в линейке X870/X870E.
Компания 3mdeb, специализирующаяся на открытом микропрограммном обеспечении, завершает масштабный проект по адаптации Coreboot и библиотеки инициализации AMD openSIL для серверной материнской платы Gigabyte MZ33-AR1. Эта плата совместима с последним поколением процессоров AMD EPYC 9005 “Turin” и доступна для массового использования, что делает её отличной платформой для демонстрации открытых прошивок.
Проект реализуется при финансовой поддержке фонда NLnet, цель которого — продвигать открытые технологии. Команда 3mdeb во главе с Михалом Жиговским выбрала MZ33-AR1 в качестве основной целевой платформы и уже добилась устойчивой загрузки как Microsoft Windows, так и Linux, завершив настройку ACPI и исправление множества ошибок. Ранее 3mdeb уже адаптировали Coreboot к настольным платам на базе Intel, а теперь сфокусировались на серверных решениях AMD.
В блоге компании подчёркивается, что без инициативы AMD openSIL реализация поддержки новой серверной микроархитектуры была бы невозможна. Проект стал важным шагом в развитии открытых прошивок для серверных платформ AMD, особенно с учётом того, что openSIL ориентирован на будущие решения на базе Zen 6.
Успешная реализация порта Coreboot+openSIL на Gigabyte MZ33-AR1 может стать отправной точкой для расширения поддержки открытых прошивок на другие современные платформы AMD, как серверные, так и клиентские.
Инженеры из Калифорнийского университета в Сан-Диего разработали принципиально новую технологию охлаждения, которая может решить проблему растущего энергопотребления ИИ-центров обработки данных. Системы охлаждения серверов являются одними из самых «прожорливых» компонентов в ЦОД, и новая разработка, использующая специально разработанную волоконную мембрану, обещает значительно снизить потребление энергии и воды.
Технология основана на принципе испарительного охлаждения. Мембрана состоит из множества взаимосвязанных микроскопических пор, которые втягивают охлаждающую жидкость за счет капиллярного действия. Система имеет трехслойную структуру: нижний слой с микроканалами для жидкости, средний слой с самой мембраной и верхний слой-испаритель. Тепло, выделяемое ИИ-ускорителем, превращает жидкость в пар, который затем эффективно уходит через верхний слой.
Этот дизайн решает ключевые проблемы предыдущих попыток испарительного охлаждения. Ранее в подобных конструкциях поры были либо слишком малы, что приводило к засорению, либо слишком велики, что вызывало нежелательное кипение теплоносителя. Новая мембрана имеет поры "идеального" размера, что предотвращает обе проблемы и обеспечивает стабильную работу.
В ходе тестов система продемонстрировала рекордный показатель теплового потока в 800 Вт на квадратный сантиметр и сохраняла полную стабильность в течение нескольких часов работы. Это делает ее чрезвычайно мощным решением для будущих поколений ИИ-ускорителей, чье энергопотребление продолжает стремительно расти.
Компания AMD представила финансовые результаты за третий квартал 2025 года, продемонстрировав значительный рост в своем ключевом сегменте Client and Gaming. Общая выручка подразделения достигла $4.0 миллиарда, что на 73% превышает показатель аналогичного периода прошлого года, составлявший $2.3 миллиарда.
Существенно выросла и прибыльность. Операционная прибыль... $867 миллионов, в то время как год назад этот показатель составлял всего $288 миллионов. Операционная маржа увеличилась с 12% до 21%, что свидетельствует о высокой эффективности бизнеса.
Рост выручки был обеспечен обоими направлениями. Клиентский сегмент (процессоры) вырос с $1.8 млрд до $2.8 млрд. В отчете это объясняется рекордными продажами процессоров Ryzen.
Игровой сегмент (видеокарты и полузаказные решения) показал еще более взрывной рост, увеличив выручку с $0.5 млрд до $1.3 млрд. Компания официально заявляет, что это обусловлено ростом доходов от полузаказных продуктов (чипов для консолей) и сильным спросом на игровые графические процессоры Radeon.
Среди других стратегических достижений квартала компания отметила запуск новых процессоров Ryzen Threadripper 9000WX и 9000X, хорошие мировые продажи портативных ПК на базе Ryzen Z2 (таких как ROG Ally Ally X), а также быстрое внедрение технологии AMD FSR 4, которая была добавлена в более чем 85 игр.
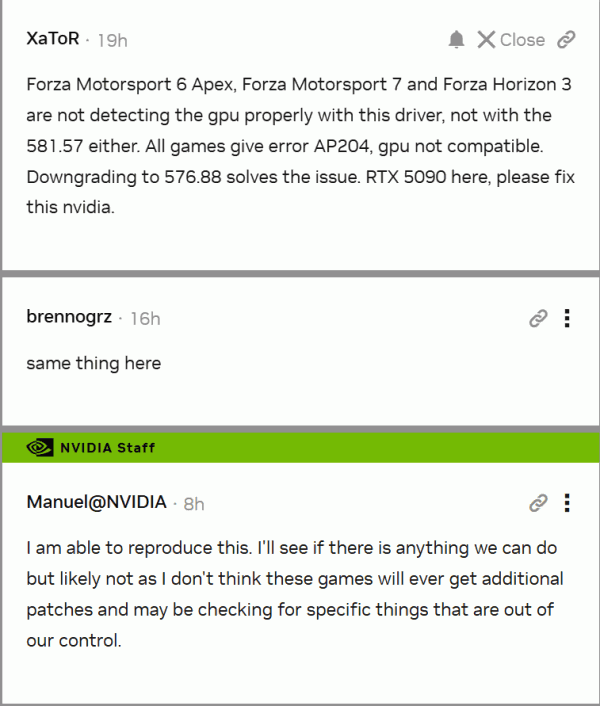
Пользователи видеокарт NVIDIA RTX 5090 столкнулись с серьёзной проблемой при запуске игр Forza Motorsport 6 Apex, Forza Motorsport 7 и Forza Horizon 3. После установки драйвера GeForce 581.57 (и более раннего 581.47) игры выдают ошибку AP204 (GPU not compatible), не распознавая видеокарту. Ошибка делает запуск невозможным.
Как отметил один из пользователей, понижение драйвера до версии 576.88 полностью решает проблему, подтверждая, что речь идёт именно о несовместимости новых драйверов с устаревшими играми. Второй пользователь подтвердил аналогичную ситуацию, а представитель NVIDIA, Manuel Guzman, сообщил, что ситуация воспроизводится в лабораторных условиях и уже проверяется внутри компании.
Однако есть важная оговорка: по словам представителя NVIDIA, маловероятно, что можно будет исправить эту ошибку на уровне драйвера. Причина в том, что данные игры больше не получают патчи, а система проверки GPU в них, скорее всего, жёстко привязана к старым ID видеокарт, не включающим новые модели. Это создаёт проблему совместимости, которую невозможно решить без участия разработчиков игр — а такие патчи уже не ожидаются.
Таким образом, владельцы RTX 5090 и новых драйверов могут остаться без доступа к ряду классических тайтлов серии Forza, если не использовать старые версии драйверов. Временное решение — даунгрейд до 576.88, но оно сопряжено с риском потери поддержки новых игр и исправлений.
Многолетнее судебное противостояние между Epic Games и Google, начавшееся в августе 2020 года, подошло к завершению. Компании объявили о достижении мирового соглашения, которое может радикально изменить экосистему Android, предоставив разработчикам больше свободы в выборе способов распространения и монетизации приложений.
Иск Epic против Google был подан одновременно с аналогичным делом против Apple. В декабре 2023 года Epic одержала полную победу над Google в суде, и это решение было подтверждено апелляциями. Даже обращение Google в Верховный суд США не принесло успеха, что в итоге привело стороны к переговорам и совместному компромиссу.
Согласно условиям соглашения, Google обязуется снизить комиссию до 20% для покупок с игровыми преимуществами и до 9% — для остальных. Также в приложениях, включая Epic Games Store, будет отображаться альтернативная система оплаты наряду с Google Play Billing. Начиная с будущей версии Android и до 30 июня 2032 года, Google позволит пользователям устанавливать сторонние магазины приложений напрямую с веб-сайтов через один экран установки, с использованием нейтрального языка интерфейса.
По словам генерального директора Epic Games Тима Суини, соглашение «открывает Android по-настоящему» и представляет собой «комплексное решение», выгодно отличающееся от «закрытой модели Apple», которая продолжает блокировать сторонние магазины. Более того, все изменения будут действовать не только в США, но и по всему миру, что делает этот шаг гораздо масштабнее прежних судебных решений.
Если суд одобрит соглашение, это официально завершит многолетний конфликт между Epic и Google.
Компания Intel официально внедряет поддержку технологии Content Adaptive Sharpening Filter (CASF) в грядущей версии ядра Linux 6.19, которая ожидается в феврале 2026 года. Работа над фильтром адаптивной резкости ведётся с начала 2024 года и впервые станет доступна в составе основного ядра, после включения в очередь DRM-Next.
CASF был представлен как часть графической подсистемы процессоров Intel Lunar Lake, запущенных в сентябре 2024 года. Однако реализация в Linux оставалась незавершённой до текущего момента. CASF не только улучшает чёткость изображения с учётом контента, но и вносит в Linux новое DRM-свойство sharpness, которое позволит унифицировать управление резкостью и использовать его в других графических драйверах ядра.
Для полноценной работы потребуется не только обновлённый драйвер ядра, но и поддержка на уровне пользовательского интерфейса. KDE Plasma 6.6 уже включает поддержку CASF через KWin, а в GNOME Mutter готовится аналогичный патч, который, как ожидается, войдёт в релиз GNOME 50, запланированный к выпуску с Ubuntu 26.04 LTS.
Помимо CASF, Intel включает в ядро Linux 6.19 и другие улучшения: поддержку Variable Rate Refresh (VRR), активацию Xe3P LT PHY, сжатие фреймбуфера (FBC) для Xe3P_LPD, а также исправления ошибок и оптимизацию кода. После завершения поддержки Panther Lake, инженеры Intel теперь сосредоточены на графической интеграции Nova Lake и Crescent Island в Linux-драйверы.
Компания AMD подтвердила получение лицензий на экспорт искусственного интеллекта-чипов Instinct MI308 в Китай, что стало важным событием на фоне сохраняющихся ограничений для NVIDIA H20. В квартальном отчёте за Q3 генеральный директор AMD Лиза Су заявила, что у компании «есть определённость» по поводу предложения для китайского рынка, и таким решением стала платформа MI308.
Хотя точные характеристики Instinct MI308 ещё не раскрыты, предполагается, что они находятся на уровне ускорителей NVIDIA H20, поскольку должны соответствовать требованиям американского экспортного контроля. Это позволяет AMD предлагать конкурентоспособное решение на рынке, где NVIDIA столкнулась с замедлением получения экспортных лицензий и сложностями в адаптации своей архитектуры под китайские стандарты.
Несмотря на полученные разрешения, AMD не включила выручку от MI308 в прогноз на Q4, ссылаясь на динамичную ситуацию и неопределённость в отношении спроса и возможностей на китайском направлении. Руководство подчеркивает, что работа с заказчиками продолжается, и только после этого можно будет говорить о потенциальных объёмах.
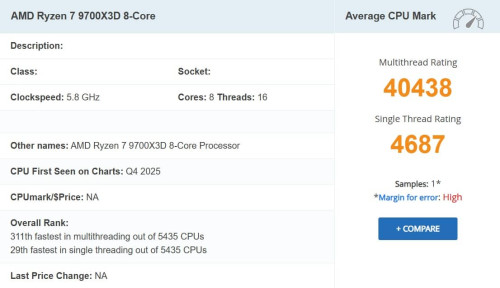
В базе данных PassMark зафиксирован процессор AMD Ryzen 7 9700X3D, построенный на архитектуре Zen 5 и оснащённый технологией 3D V-Cache. Чип имеет 8 ядер и 16 потоков, а его заявленная максимальная частота составляет 5.8 ГГц, что вызывает сомнения — такие показатели не характерны даже для старших моделей новой линейки.
В тесте PassMark 9700X3D набрал 40438 баллов в многопоточном режиме и 4687 — в однопоточном. Это соответствует 311-му месту по мультипоточности и 29-му по производительности на одно ядро среди более 5000 протестированных CPU. Однако в базе указана только одна запись, что делает результаты предварительными и возможно неточными.
Учитывая, что даже Ryzen 9 9850X3D работает на частотах до 5.6 ГГц, цифра в 5.8 ГГц выглядит маловероятной. Это может быть следствием ошибки в тестировании, ручного разгона или некорректного считывания данных. Сам факт появления 9700X3D может свидетельствовать о подготовке расширенной серии Ryzen 9000X3D, но пока подтверждений от AMD нет.
Если Ryzen 7 9700X3D поступит в розничную продажу, он может занять нишу высокопроизводительного геймерского CPU с упором на низкие задержки и высокий FPS за счёт дополнительного кеша.