GeForce 4 Ti 4200 особенности архитектуры
Основные архитектурные новшества NV25 (в сравнении с NV20)
Два независимых контроллера отображения (CRTC). Гибкая поддержка всевозможных режимов с выводом двух независимых по разрешению и содержанию буферов кадра на любые доступные приемники сигнала.
Два полноценных интегрированных в чип 350 МГц RAMDAC (с 10 битной палитрой).
Интегрированный в чип интерфейс TV-Out.
Интегрированный в чип TDMS трансмиттер (для DVI интерфейса).
Два блока интерпретации и исполнения вершинных шейдеров. Они сулят существенное увеличение скорости обработки сцен со сложной геометрией. Блоки не могут испольнять различный микрокод шейдеров, единственное назначение подобного дублирования - обработка двух вершин одновременно - служит для увеличения производительности.
Усовершенствованные конвейеры закраски обеспечивают аппаратную поддержку пиксельных шейдеров до версии 1.3 включительно.
По заявлениям NVIDIA, увеличена эффективная скорость закраски в режимах MSAA, теперь режимы 2x AA и Quincunx AA вызовут существенно меньшее падение производительности. Немного усовершенствован Quincunx AA (смещены позиции выборки семплов). Появился новый метод AA - 4xS.
Усовершенствованная система раздельного кеширования (4 раздельных кеша для геометрии, текстур, буфера кадра и Z буфера).
Усовершенствованное сжатие без потерь (1:4) и быстрая очистка Z буфера.
Усовершенствованный алгоритм отброса невидимых поверхностей (Z Cull HSR).
Подводя итог этого списка, хочется отметить скорее эволюционный, нежели революционный характер изменений в сравнении с предыдущим творением NVIDIA (NV20). Впрочем, это неудивительно - исторически NVIDIA вначале предлагала продукт, несущий множество новых технологий, а затем выпускала более совершенный (оптимизированный) вариант на его основе, устраняя привлекшие основное внимание (за время присутствия продукта на рынке) недостатки.
Структурная схема N25
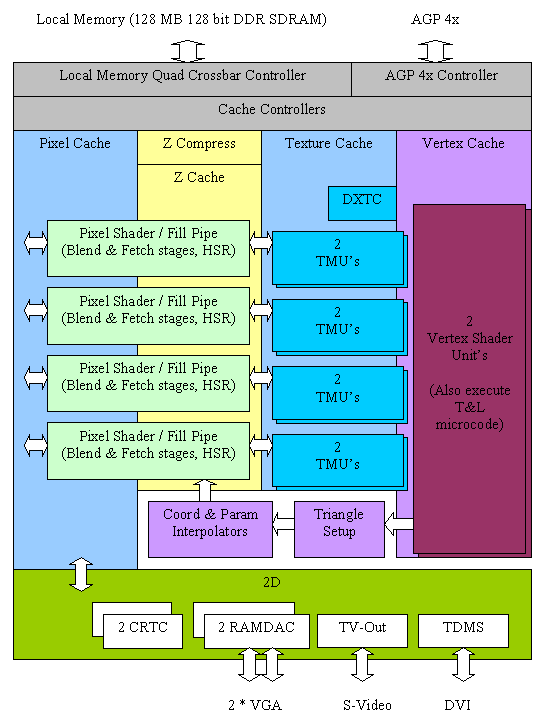
По проведенному после выхода видеокарт тестированию GeForce4 Ti оказывалась ощутимо быстрее GeForce3 Ti. Такой впечатляющий отрыв в производительности NV25 был достигнут не благодаря какой-то принципиально новой технологии, а по причине дальнейшей отладки и настройки существующих в GeForce3 (NV20) технологий. Имейтся в виду, что ядро GeForce4 было всего на 5% больше ядра NV20 при равном техпроцессе (0,15 мкм).
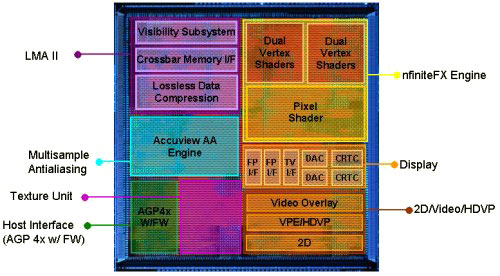
Вершинные шейдеры nfiniteFX II
Если GeForce3 имела только один модуль вершинных шейдеров, то в GeForce4 Ti их уже два. Впрочем, вряд ли вас это удивит, поскольку в чипе nVidia для Microsoft Xbox также присутствует два модуля вершинных шейдеров. Разве что в NV25 модули были улучшены.
Очевидно, что два параллельно работающих модуля вершинных шейдеров могли обработать больше вершин в единицу времени. Для этого чип сам раскладывал вершины на два потока, поэтому новый механизм прозрачен для приложений и API. Диспетчеризация инструкций осуществляется NV25, при этом чип должен убедиться, что каждый модуль вершинных шейдеров работает над своей вершиной. Улучшение модулей вершинных шейдеров со времен GeForce3 привело к уменьшению задержек при обработке инструкций.
В итоге GeForce4 Ti4600 мог обработать примерно в 3 раза больше вершин, чем GeForce3 Ti500 по причине наличия двух модулей вершинных шейдеров, их улучшения и работе на более высокой тактовой частоте.
Пиксельные шейдеры nfiniteFX II
nVidia смогла улучшить функциональность пиксельных шейдеров в GeForce4 Ti.
Новый чип поддерживает пиксельные шейдеры 1.2 и 1.3, но не расширение ATi 1.4.
Ниже приведены новые режимы пиксельных шейдеров.
OFFSET_PROJECTIVE_TEXTURE_2D_NV
OFFSET_PROJECTIVE_TEXTURE_2D_SCALE_NV
OFFSET_PROJECTIVE_TEXTURE_RECTANGLE_NV
OFFSET_PROJECTIVE_TEXTURE_RECTANGLE_SCALE_NV
OFFSET_HILO_TEXTURE_2D_NV
OFFSET_HILO_TEXTURE_RECTANGLE_NV
OFFSET_HILO_PROJECTIVE_TEXTURE_2D_NV
OFFSET_HILO_PROJECTIVE_TEXTURE_RECTANGLE_NV
DEPENDENT_HILO_TEXTURE_2D_NV
DEPENDENT_RGB_TEXTURE_3D_NV
DEPENDENT_RGB_TEXTURE_CUBE_MAP_NV
DOT_PRODUCT_TEXTURE_1D_NV
DOT_PRODUCT_PASS_THROUGH_NV
DOT_PRODUCT_AFFINE_DEPTH_REPLACE_NV
Мы не будем описывать каждый новый режим, но следует отметить появившуюся в GeForce4 Ti поддержку скорректированного по z наложения неровностей (z-correct bump mapping), что позволяло устранить артефакты, появляющиеся при соприкосновении bump-текстуры с другой геометрией (например, когда вода в озере или реке соприкасается с землей).
nVidia в конце концов смогла улучшить конвейер пиксельных шейдеров, что ощутимо отразилось на скорости рендеринга сцен с 3-4 текстурами на пиксель.

Accuview - улучшенное сглаживание Во время выпуска GeForce3 nVidia анонсировала сглаживание HRAA - сглаживание на высоком разрешении, базирующееся на многосэмпловом полноэкранном сглаживании. В GeForce4 было реализовано сглаживание Accuview, по сути являющееся улучшенным многосэмпловым сглаживанием, как в отношении качества, так и производительности.
nVidia сместила позиции сэмплов, что должно улучшить качество сглаживания по причине накопления меньшего количества ошибок, особенно при использовании сглаживания Quincunx. nVidia выпустила документацию по этой процедуре, но вряд ли имел смысл ее читать, поскольку она мало что объясняла. Новая технология фильтрации включалась каждый раз, когда сэмплы совмещались на финальном сглаженном кадре, причем технология позволяла экономить одну полную запись в кадровый буфер, что в свою очередь значительно сказывалось на производительности сглаживания.
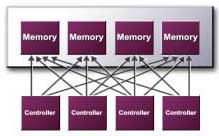
LMA II - новая архитектура памяти Именно благодаря улучшениям в архитектуре памяти GeForce4 Ti показывала столь сильный отрыв от GeForce3.
В GeForce3/GeForce4 контроллер памяти разделяелся на четыре независимых контроллера, каждый из которых использует выделенную 32-битную DDR шину. Все запросы к памяти разделялись между этими контроллерами.
В LMA II практически каждый компонент подвергся улучшениям. Можно обратить внимание на четыре кэша. Но кэширование - исключительная черта GeForce, поскольку в Radeon 8500 также присутствовали аналогичные кэши. Вообще кэшированию в графических чипах уделяелось намного меньше внимания, чем кэшам в процессорах, поскольку их размер не былстоль велик. Причина этого понятна: графические чипы работали тогда медленнее шин памяти, в то время как центральные процессоры работли в 2-16 раз быстрее, поэтому кэш играл там намного более важную роль.
Перекрестный контроллер памяти (crossbar memory controller)
В GeForce3 уже присутствовал этот контроллер, позволяющий осуществлять 64-битную, 128-битную и обычную 256-битную передачу, что значительно улучшал пропускную способность. В LMA II nVidia улучшила алгоритмы балансировки нагрузки для различных разделов памяти и модернизировала схему приоритетов.
Визуальная подсистема (visibility subsystem) - отбрасывание перекрытых пикселей
Эта технология уже существовала в GeForce3, но в NV25 она была улучшена для более точной отбраковки пикселей с использованием меньшей пропускной способности памяти. Отбраковка тогда производилась с помощью специального кэша на чипе, что позволяло уменьшить обращение к внешней памяти видеокарты. Как показало исследование Anandtech, GeForce4 на 25% лучше отбраковывал пиксели, чем GeForce3 при равной тактовой частоте.
Компрессия Z-буфера без потерь
И опять же, эта возможность существовала в GeForce3, но благодаря новому алгоритму сжатия в LMA II чаще достигалась успешная компрессия 4:1.
Кэш вершин
Сохраняет вершины после того как они были посланы по AGP. Благодаря кэшу улучшалось использование AGP, поскольку он позволял избежать передачи одинаковых вершин (например, если примитивы имели общие границы).
Кэш примитивов
Накапливал примитивы после их обработки (после вершинного шейдера) в фундаментальные примитивы для передачи на модуль установки треугольников.
Двойной кэш текстур
Уже существовал на GeForce3. Новые алгоритмы лучше работали при использовании мультитекстурирования или высококачественной фильтрации. Благодаря этому в GeForce4 Ti была значительно улучшена производительность при наложении 3-4 текстур.
Пиксельный кэш
Кэш использовался в конце конвейера рендеринга для накопления, очень похожего на функцию в процессорах Intel/AMD. Кэш накаплиал некоторое количество пикселей и потом в пакетном режиме записывал их в память.
Автоматическая предварительная зарядка (pre-charge)
Перед чтением из банка памяти необходимо сделать его предварительную зарядку, что приводит к задержкам. GeForce4 Ti мог упреждающе проводить зарядку, используя специальный алгоритм предсказания.
Быстрая Z-очистка (Z-clear)
Эта возможность уже некоторое время была известна и использовалась в других чипах. Первый раз быстрая Z-очистка была задействована в чипе ATi Radeon. Она попросту устанавливала флаг для определенного участка кадрового буфера, так что вместо заполнения этого участка нулями, можно всего было лишь выставить флаг, что позволяло экономить пропускную способность памяти.

Характеристики NVIDIA GeForce 4 Ti 4200
| Наименование | GeForce 4 Ti 4200 |
| Ядро | NV25 |
| Техпроцесс (мкм) | 0,15 |
| Транзисторов (млн) | 63 |
| Частота работы ядра | 250 |
| Частота работы памяти (DDR) | 222 (444) |
| Шина и тип памяти | DDR-128 bit |
| ПСП (Гб/с) | 7,1 |
| Пиксельных конвейеров | 4 |
| TMU на конвейер | 2 |
| Текстур за такт | 8 |
| Текстур за проход | 4 |
| Вершинных конвейеров | 2 |
| Pixel Shaders | 1,3 |
| Vertex Shaders | 1,1 |
| Fill Rate (Mpix/s) | 1000 |
| Fill Rate (Mtex/s) | 2000 |
| DirectX | 8.0 |
| Anti-Aliasing (Max) | MS - 4x |
| Анизотропная фильтрация (Max) | 8x |
| Объем памяти | 64 / 128 MB |
| Интерфейс | AGP 4x |
| RAMDAC | 2x350 MHz |
GeForce4 Ti 4200 - это облегченный вариант карт GeForce4 Ti 4600 или 4400, имеел более низкую тактовую частоту, но и стоил значительно дешевле.
Во многом карту GeForce4 Ti 4200 можно считать потенциальным "могильщиком" линейки GeForce3 Ti 500. Если бы видеокарта Ti 4200, сочетающая в себе высокую производительность с низкой ценой, была бы выпущена одновременно с более дорогими моделями GeForce4 Ti 4600 и 4400, ситуация была бы явно не в пользу последних. Поэтому NVIDIA задержала выпуск Ti 4200 до более позднего срока, пока не произошло значительное снижения объем продаж в линейке GeForce3.
Mafia